
Neural Networks from Scratch - P.5 Hidden Layer Activation Functions. Simple Grad - Colaboratory. Reverse-mode automatic differentiation from scratch, in Python. Automatic differentiation is the foundation upon which deep learning frameworks lie.

Deep learning models are typically trained using gradient based techniques, and autodiff makes it easy to get gradients, even from enormous, complex models. ‘Reverse-mode autodiff’ is the autodiff method used by most deep learning frameworks, due to its efficiency and accuracy. Let’s: Look at how reverse-mode autodiff works. Create a minimal autodiff framework in Python. The small autodiff framework will deal with scalars. Note on terminology: from now on ‘autodiff’ will refer to ‘reverse-mode autodiff’. How does autodiff work? Let’s start with an example. a = 4b = 3c = a + b # = 4 + 3 = 7 d = a * c # = 4 * 7 = 28 Q1: What is the gradient of d with respect to a, i.e.
Solving the ‘traditional’ way: There’s many ways to solve Q1, but let’s use the product rule, i.e. if y=x1x2 then y′=x′1x2+x1x′2. Phew… and if you wanted to know ∂d∂b you’d have to carry out the process again. Solving the autodiff way. Neural Networks from Scratch. TensorFlow, Keras and deep learning, without a PhD. Understanding 1D and 3D Convolution Neural Network. Before going through Conv1D, let me give you a hint.
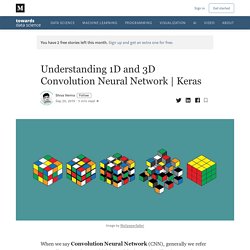
In Conv1D, kernel slides along one dimension. Now let’s pause the blog here and think which type of data requires kernel sliding in only one dimension and have spatial properties? The answer is Time-Series data. Let’s look at the following data. This data is collected from an accelerometer which a person is wearing on his arm. Following plot illustrate how the kernel will move on accelerometer data.
Following is the code to add a Conv1D layer in keras. Argument input_shape (120, 3), represents 120 time-steps with 3 data points in each time step. Gradient Descent Derivation · Chris McCormick. 04 Mar 2014 Andrew Ng’s course on Machine Learning at Coursera provides an excellent explanation of gradient descent for linear regression.

To really get a strong grasp on it, I decided to work through some of the derivations and some simple examples here. This material assumes some familiarity with linear regression, and is primarily intended to provide additional insight into the gradient descent technique, not linear regression in general. I am making use of the same notation as the Coursera course, so it will be most helpful for students of that course.
For linear regression, we have a linear hypothesis function, . Intro to optimization in deep learning: Momentum, RMSProp and Adam. In another post, we covered the nuts and bolts of Stochastic Gradient Descent and how to address problems like getting stuck in a local minima or a saddle point.
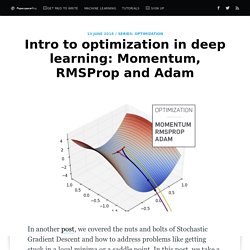
In this post, we take a look at another problem that plagues training of neural networks, pathological curvature. While local minima and saddle points can stall our training, pathological curvature can slow down training to an extent that the machine learning practitioner might think that search has converged to a sub-optimal minma. Let us understand in depth what pathological curvature is. Joel Grus - Livecoding Madness - Let's Build a Deep Learning Library. Anatomy of a High-Performance Convolution. On my not-too-shabby laptop CPU, I can run most common CNN models in (at most) 10-100 milliseconds, with libraries like TensorFlow.
In 2019, even a smartphone can run “heavy” CNN models (like ResNet) in less than half a second. So imagine my surprise when I timed my own simple implementation of a convolution layer and found that it took over 2 seconds for a single layer! It’s no surprise that modern deep-learning libraries have production-level, highly-optimized implementations of most operations. But what exactly is the black magic that these libraries use that we mere mortals don’t? [D] What is the software used to draw nice CNN models? : MachineLearning. CNNs, Part 1: An Introduction to Convolutional Neural Networks - victorzhou.com. Notes on Weight Initialization for Deep Neural Networks – Aman Madaan. Initialization. A Recipe for Training Neural Networks. Some few weeks ago I posted a tweet on “the most common neural net mistakes”, listing a few common gotchas related to training neural nets.
The tweet got quite a bit more engagement than I anticipated (including a webinar :)). Clearly, a lot of people have personally encountered the large gap between “here is how a convolutional layer works” and “our convnet achieves state of the art results”. So I thought it could be fun to brush off my dusty blog to expand my tweet to the long form that this topic deserves. However, instead of going into an enumeration of more common errors or fleshing them out, I wanted to dig a bit deeper and talk about how one can avoid making these errors altogether (or fix them very fast). The trick to doing so is to follow a certain process, which as far as I can tell is not very often documented. Machine Learning for Beginners: An Introduction to Neural Networks - victorzhou.com. Here’s something that might surprise you: neural networks aren’t that complicated!

The term “neural network” gets used as a buzzword a lot, but in reality they’re often much simpler than people imagine. This post is intended for complete beginners and assumes ZERO prior knowledge of machine learning. We’ll understand how neural networks work while implementing one from scratch in Python. Let’s get started! 1. Understanding Convolutions. In a previous post, we built up an understanding of convolutional neural networks, without referring to any significant mathematics.

To go further, however, we need to understand convolutions. If we just wanted to understand convolutional neural networks, it might suffice to roughly understand convolutions. What is the difference between 'SAME' and 'VALID' padding in tf.nn.max_pool of tensorflow? Max Pooling is an operation to reduce the input dimensionality.

The output is computed by taking maximum input values from intersecting input patches and a sliding filter window. At each step, the position of the filter window is updated according to the strides argument. When applying the filter to the border pixels some of the elements of the filter may not overlap the input elements.
Therefore, in order to compute the values of those border regions input may be extended by padding with zero values. In some cases, we may want to discard these border regions. Tf.nn.max_pool of tensorflow supports two types of padding, 'VALID' and 'SAME'. How does Batch Normalization Help Optimization? – gradient science. Supervised deep learning is, by now, relatively stable from an engineering point of view.

Training an image classifier on any dataset can be done with ease, and requires little of the architecture, hyperparameter, and infrastructure tinkering that was needed just a few years ago. Nevertheless, getting a precise understanding of how different elements of the framework play their part in making deep learning stable remains a challenge. Today, we explore this challenge in the context of batch normalization (BatchNorm), one of the most widely used tools in modern deep learning. Broadly speaking, BatchNorm is a technique that aims to whiten activation distributions by controlling the mean and standard deviation of layer outputs (across a batch of examples).
Specifically, for an activation of layer , we have that: \begin{equation} BN(y_j)^{(b)} = \gamma \cdot \left(\frac{y_j^{(b)} - \mu(y_j)}{\sigma(y_j)}\right) + \beta, \end{equation} The story so far. Jane Street Tech Blog - L2 Regularization and Batch Norm. This blog post is about an interesting detail about machine learning that I came across as a researcher at Jane Street - that of the interaction between L2 regularization, also known as weight decay, and batch normalization.
In particular, when used together with batch normalization in a convolutional neural net with typical architectures, an L2 objective penalty no longer has its original regularizing effect. Instead it becomes essentially equivalent to an adaptive adjustment of the learning rate! This and similar interactions are already part of the awareness in the wider ML literature, for example in Laarhoven or Hoffer et al..
But from my experience at conferences and talking to other researchers, I’ve found it to be surprisingly easy to forget or overlook, particularly considering how commonly both batch norm and weight decay are used. For this blog post, we’ll assume that model fitting is done via stochastic gradient descent. L2 Regularization / Weight Decay Purpose/Intuition. Hacker's guide to Neural Networks. Hi there, I’m a CS PhD student at Stanford. I’ve worked on Deep Learning for a few years as part of my research and among several of my related pet projects is ConvNetJS - a Javascript library for training Neural Networks.
Javascript allows one to nicely visualize what’s going on and to play around with the various hyperparameter settings, but I still regularly hear from people who ask for a more thorough treatment of the topic. This article (which I plan to slowly expand out to lengths of a few book chapters) is my humble attempt. It’s on web instead of PDF because all books should be, and eventually it will hopefully include animations/demos etc. My personal experience with Neural Networks is that everything became much clearer when I started ignoring full-page, dense derivations of backpropagation equations and just started writing code. “…everything became much clearer when I started writing code.” 10 Gradient Descent Optimisation Algorithms.
How to build your own Neural Network from scratch in Python. Motivation: As part of my personal journey to gain a better understanding of Deep Learning, I’ve decided to build a Neural Network from scratch without a deep learning library like TensorFlow. I believe that understanding the inner workings of a Neural Network is important to any aspiring Data Scientist.
This article contains what I’ve learned, and hopefully it’ll be useful for you as well! Most introductory texts to Neural Networks brings up brain analogies when describing them. Without delving into brain analogies, I find it easier to simply describe Neural Networks as a mathematical function that maps a given input to a desired output. Neural Networks consist of the following components An input layer, xAn arbitrary amount of hidden layersAn output layer, ŷA set of weights and biases between each layer, W and bA choice of activation function for each hidden layer, σ. Neural Network Simulator. Thomas-tanay.github. How to build your own Neural Network from scratch in Python. Convolutional Neural Networks For All. Batch Normalization — What the hey? – Gab41. Differences between L1 and L2 as Loss Function and Regularization. [2014/11/30: Updated the L1-norm vs L2-norm loss function via a programmatic validated diagram.
Thanks readers for the pointing out the confusing diagram. Next time I will not draw mspaint but actually plot it out.] While practicing machine learning, you may have come upon a choice of the mysterious L1 vs L2. A Quick Introduction to Neural Networks – the data science blog. Part 1 - Computational graphs - pvigier's blog. Part 1 - Computational graphs. j1994thebasic. How to debug neural networks. Manual. – Machine Learning World.
CS231n Convolutional Neural Networks for Visual Recognition. Calculus on Computational Graphs: Backpropagation. Posted on August 31, 2015. Build a Neural Network with Python. "Hello world" in Keras (or, Scikit-learn versus Keras) Neural networks - How does the Rectified Linear Unit (ReLU) activation function produce non-linear interaction of its inputs? - Cross Validated. Demystifying Deep Convolutional Neural Networks - Adam Harley (2014) Adam Harley (adam.harley<at>ryerson.ca) Version 1.1 Abstract. Implementing a Neural Network from Scratch in Python – An Introduction. Get the code: To follow along, all the code is also available as an iPython notebook on Github. How to create a Neural Network in JavaScript in only 30 lines of code. Visualising Activation Functions in Neural Networks - dashee87.github.io.
An Intuitive Explanation of Convolutional Neural Networks – the data science blog. CS231n Winter 2016: Lecture 4: Backpropagation, Neural Networks 1. A Neural Network in 11 lines of Python (Part 1) - i am trask. How To Create A Neural Network in JavaScript - Scrimba screencast. An overview of gradient descent optimization algorithms. Neural Networks in Javascript. A Beginner's Guide To Understanding Convolutional Neural Networks – Adit Deshpande – CS Undergrad at UCLA ('19)
Neural Network Architectures. How do Convolutional Neural Networks work? A Visual and Interactive Guide to the Basics of Neural Networks – J Alammar – Explorations in touchable pixels and intelligent androids. Yes you should understand backprop – Andrej Karpathy – Medium. A Neural Network Playground. Artificial Neural Networks: Mathematics of Backpropagation (Part 4) — BRIAN DOLHANSKY.
Home - colah's blog. The Neural Network Zoo - The Asimov Institute.