
Example . An example of nested downloads using RCurl. This example uses RCurl to download an HTML document and then collect the name of each link within that document.

The purpose of the example is to illustrate how we can combine the RCurl package to download a document and use this directly within the XML (or HTML) parser without having the entire content of the document in memory. We start the download and pass a function to the xmlEventParse() function for processing. As that XML parser needs more input, it fetches more data from the HTTP response stream. This is useful for handling very large data that is returned from Web queries. To do this, we need to use the multi interface for libcurl in order to have asynchronous or non-blocking downloading of the document. The remaining part is how we combine these pieces with RCurl and the XML packages to do the parsing in this asynchronous, interleaved manner.
The steps in the code are as explained as follows. Perform = FALSE . Algorithmic Trading with IBrokers. Models Collecting Dust? How to Transform Your Results from Interesting to Impactful. Data science, machine learning, and analytics have re-defined how we look at the world.
The R community plays a vital role in that transformation and the R language continues to be the de-facto choice for statistical computing, data analysis, and many machine learning scenarios. The importance of R was first recognized by the SQL Server team back in 2016 with the launch of SQL ML Services and R Server. Over the years we have added Python to SQL ML Services in 2017 and Java support through our language extensions in 2019. Earlier this year we also announced the general availability of SQL ML Services into Azure SQL Managed Instance. SparkR, sparklyr, and PySpark are also available as part of SQL Server Big Data Clusters. With that said, much has changed in the world of data science and analytics since 2016. Today we are making the following announcements to clearly state our direction and intent for R within Azure SQL and SQL Server.
Looking to the future with the R community. Pretty R syntax highlighter. R - What is the difference between gc() and rm() Memory Available for Data Storage. Models Collecting Dust? How to Transform Your Results from Interesting to Impactful. Revolution R Enterprise 5.0 now available for free academic download. Revolution Analytics - Commercial Software & Support for the R Statistics Language. “Credit to whom credit is due” – Bloganalysen mit Google und R « LIBREAS.Library Ideas. Angeregt vom wachsenden Interesse quantitativen Untersuchungen über die Wirkung von Bloginhalten, wie zuletzt im Beitrag Blogs als Quellen in der bibliothekarischen Fachkommunikation, lässt sich ebenfalls die Verlinkung innerhalb von Blogs näher explorieren.
Um schnell an möglichen Daten zu gelangen, erscheint vielversprechend. Untitled. The Comprehensive Perl Archive Network - www.cpan.org. Extracting comments from a Blogger.com blog post with R. Note #1: Check out this very useful post by Najko Jahn describing how to extract links to blogs via Google Blog Search .
Note #2: I’ll update the code below once I find the time using Najko’s cleaner XPath-based solution. Recently I’ve been working with comments as part of the project on science blogging we’re doing at the Junior Researchers Group “Science and the Internet” . I wrote the script below to quickly extract comments from Atom feeds, such as those generated by Blogger.com . The code isn’t exactly pretty, mostly because I didn’t use an XML parser to properly read the data, instead resorting to brute-force pattern matching, but it gets the job done. HtmlToText(): Extracting Text from HTML via XPath. Converting HTML to plain text usually involves stripping out the HTML tags whilst preserving the most basic of formatting.
I wrote a function to do this which works as follows (code can be found on github): The above uses an XPath approach to achieve it’s goal. Another approach would be to use a regular expression. These two approaches are briefly discussed below: GScholarXScraper: Hacking the GScholarScraper function with XPath. Kay Cichini recently wrote a word-cloud R function called GScholarScraper on his blog which when given a search string will scrape the associated search results returned by Google Scholar, across pages, and then produce a word-cloud visualisation.
This was of interest to me because around the same time I posted an independent Google Scholar scraper function get_google_scholar_df() which does a similar job of the scraping part of Kay’s function using XPath (whereas he had used Regular Expressions). My function worked as follows: when given a Google Scholar URL it will extract as much information as it can from each search result on the URL webpage into different columns of a dataframe structure. In the comments of his blog post I figured it’d be fun to hack his function to provide an XPath alternative, GScholarXScraper. I think that’s pretty much everything I added. JGR « Fells Stats. A GUI for R - Downloading And Installing Deducer. A Spatial Data Analysis GUI for R « Fells Stats. Eclipse IDE for R. Background: Eclipse is an open source Integrated Development Environment (IDE).
As with Microsoft's Visual Studio product, Eclipse is programming language-agnostic and supports any language having a suitable plugin for the IDE platform. For Eclipse, the R language plugin is StatET. RForge.net - development environment for R package developers. Free Development software downloads. R-Extension. Web scraping - Extract Links from Webpage using R. R - extracting node information. Pretty R syntax highlighter.
Pretty R syntax highlighter. Questions containing '[r] xml xpath' R - How do I scrape multiple pages with XML and ReadHTMLTable. Xml - Web scraping with R over real estate ads. R preferred by Kaggle competitors. Blog-Reference-Functions/R at master · tonybreyal/Blog-Reference-Functions. Blog-Reference-Functions/R/googleScholarXScraper/googleScholarXScraper.R at master · tonybreyal/Blog-Reference-Functions.
Facebook Graph API Explorer with R (on Windows) « Consistently Infrequent. Good GUI for R suitable for a beginner wanting to learn programming in R? - Statistical Analysis - Stack Exchange. A Spatial Data Analysis GUI for R. R] Downloading data from from internet. Web scraping. Web scraping You are encouraged to solve this task according to the task description, using any language you may know.
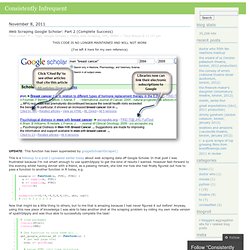
Create a program that downloads the time from this URL: and then prints the current UTC time by extracting just the UTC time from the web page's HTML. If possible, only use libraries that come at no extra monetary cost with the programming language and that are widely available and popular such as CPAN for Perl or Boost for C++. [edit] Ada [edit] AutoHotkey. Sorenmacbeth/googleanalytics4r. R - How to transform XML data into a data.frame. Web Scraping Google Scholar (Partial Success) « Consistently Infrequent. Library(XML)
Web Scraping Google Scholar: Part 2 (Complete Success) « Consistently Infrequent. Library(RCurl) library(XML)
Comment faire pour transformer les données XML dans un data.frame? J'essaie d'apprendre R XML paquet. J'essaie de créer un data.frame échantillon books.xml fichier de données XML. [BioC] PostForm() with KEGG. Blog-Reference-Functions/R/googlePlusXScraper/googlePlusXScraper.R at master · tonybreyal/Blog-Reference-Functions. Untitled. Untitled. Re: [R] Need help extracting info from XML file using XML package. XML package help. Library(XML) url <- " On research, visualization and productivity.
Web Scraping Google Scholar (Partial Success) Web Scraping Google Scholar: Part 2 (Complete Success) When Venn diagrams are not enough – Visualizing overlapping data with Social Network Analysis in R. Untitled. Abstract The idea here is to provide simple examples of how to get started with processing XML in R using some reasonably straightforward "flat" XML files and not worrying about efficiency. Here is an example of a simple file in XML containing grades for students for three different tests. <? Xml version="1.0" ? A Short Introduction to the XML package for R. To parse an XML document, you can use xmlInternalTreeParse() or xmlTreeParse() (with useInternalNodes specified as TRUE or FALSE) or xmlEventParse() .
If you are dealing with HTML content which is frequently malformed (i.e. nodes not terminated, attributes not quoted, etc.), you can use htmlTreeParse() . You can give these functions the name of a file, a URL (HTTP or FTP) or XML text that you have previously created or read from a file. If you are working with small to moderately sized XML files, it is easiest to use xmlInternalTreeParse() to first read the XML tree into memory.
#" doc = xmlInternalTreeParse("Install/Web/index.html.in") Then you can traverse the tree looking for the information you want and putting it into different forms. Many people find recursion confusing, and when coupled with the need for non-local variables and mutable state, a different approach can be welcome. Memory Management in the the XML Package. Memory Management in the the XML Package Duncan Temple Lang University of California at Davis Department of Statistics Abstract We describe some of the complexities of memory management in the XML package. The XML package. It's crantastic! Tools for parsing and generating XML within R and S-Plus.. This package provides many approaches for both reading and creating XML (and HTML) documents (including DTDs), both local and accessible via HTTP or FTP.
It also offers access to an XPath "interpreter". Maintainer: Duncan Temple Lang Author(s): Duncan Temple Lang (duncan@r-project.org) License: BSD Released 10 months ago. 28 previous versions XML_3.96-1.1. Ratings Log in to vote. Grabbing Tables in Webpages Using the XML Package. The Omega Project for Statistical Computing. RCurl. RStudio. Romain Francois, Professional R Enthusiast. R: Web Scraping R-bloggers Facebook Page « Consistently Infrequent. Introduction R-bloggers.com is a blog aggregator maintained by Tal Galili. R: A Quick Scrape of Top Grossing Films from boxofficemojo.com « Consistently Infrequent. Untitled. [R] Need help extracting info from XML file using XML package from Don MacQueen on 2009-03-02 (R help archive) Package XML. CRAN - Package somplot.