
Best machine learning algorithms you should know – Data Science Blog. Machine learning is a key technology tool businesses use to build tools that enhance their operations.
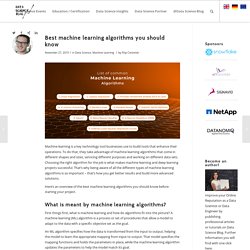
To do that, they take advantage of machine learning algorithms that come in different shapes and sizes, servicing different purposes and working on different data sets. Choosing the right algorithm for the job is what makes machine learning and deep learning projects successful. That’s why being aware of all the different types of machine learning algorithms is so important – that’s how you get better results and build more advanced solutions. Here’s an overview of the best machine learning algorithms you should know before starting your project. What is meant by machine learning algorithms? First things first, what is machine learning and how do algorithms fit into the picture? Data Mining Algorithms in ELKI. Standardabweichung. Die Standardabweichung ist ein Maß dafür, wie weit die einzelnen Zahlen verteilt sind.
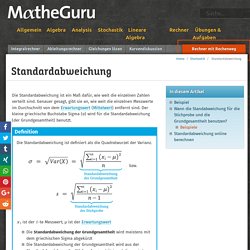
Genauer gesagt, gibt sie an, wie weit die einzelnen Messwerte im Durchschnitt von dem Erwartungswert (Mittelwert) entfernt sind. Der kleine griechische Buchstabe Sigma (σ) wird für die Standardabweichung (der Grundgesamtheit) benutzt. Definition Die Standardabweichung ist definiert als die Quadratwurzel der Varianz. bzw. Mathe by Daniel Jung. Amazon. MachineX: Why No One Uses an Apriori Algorithm for Association Rule Learning - DZone AI. In my previous blog, MachineX: Two Parts of Association Rule Learning, we discussed that there are two parts in performing association rule learning, namely, frequent itemset generation and rule generation.
In this blog, we are going to talk about one of the algorithms for frequent itemset generation, in other words, Apriori algorithm. Bayessche Statistik. Die bayessche Statistik ist ein Zweig der Statistik, der mit dem bayesschen Wahrscheinlichkeitsbegriff und dem Satz von Bayes Fragestellungen der Stochastik untersucht.
Der Fokus auf diese beiden Grundpfeiler begründet die bayessche Statistik als eigene „Stilrichtung“. Klassische und bayessche Statistik führen teilweise zu den gleichen Ergebnissen,[1] sind aber nicht vollständig äquivalent. Charakteristisch für bayessche Statistik ist die konsequente Verwendung von Wahrscheinlichkeitsverteilungen bzw. Randverteilungen, deren Form die Genauigkeit der Verfahren bzw. Verlässlichkeit der Daten und des Verfahrens transportiert. Der bayessche Wahrscheinlichkeitsbegriff setzt keine unendlich oft wiederholbaren Zufallsexperimente voraus, so dass bayessche Methoden auch bei kleiner Datengrundlage verwendbar sind. Aufgrund der strengen Betrachtung von Wahrscheinlichkeitsverteilungen sind bayessche Verfahren oft rechnerisch aufwändig. Apriori vs FP-Growth for Frequent Item Set Mining. Frequent Item Set (FIS) mining is an essential part of many Machine Learning algorithms.

What this technique is intended to do is to extract the most frequent and largest item sets within a big list of transactions containing several items each. For example: Let T be a list of n transactions [t1, t2, ..., tn]. Each transaction ti contains a list of kt items [ai1, a2i, ..., aik]. So we have = [ t1 = [a11, a12, ... a1k], t2 = [a21, a22, ... a2k], ..., tk = [at1, at2, ... atk] ]. The Frequent Item Set for is , where ∀s ∈ , s is the most frequent and largest set of items, which: Is not contained within another set in Appears at least times (we call this number as the minimum support threshold). An example of this FIS technique, a customer Mario, with a minimum support threshold m of 50 % and we want to mine the FIS for Mario.
Funktionen. Über die Mathematik wird versucht, Zusammenhänge in der realen Welt mathematisch zu beschreiben.

Dazu werden von der realen Welt Modelle gebildet, die den vermuteten Zusammenhang beschreiben. Dieser Zusammenhang wird Funktion genannt. Z. B. hängt der Siedepunkt von Wasser von dem Luftdruck ab. In einem Tal ist der Wassersiedepunkt höher als auf einem Berg, denn dort ist der Luftdruck geringer. In diesem Modell hängt die veränderliche Größe Siedepunkt (y) von der variablen Größe Luftdruck (x) ab. Y ist eine Funktion von x und wird in der mathematischen Schreibweise wie folgt dargestellt... y = f(x) (explizite Darstellungsform). ... und wird gelesen als “y ist gleich f von x” wobei, f für Funktion,x für die unabhängige Variable undy für die abhängige Variable steht.
Eine Funktion f ist eine Zuordnung, die jeder Zahl x einer Zahlenmenge D eine Zahl y aus der Zahlenmenge W zuordnet.Die Zuordnung ist eindeutig, d. h., jeder Zahl x wird genau eine Zahl y zugeordnet. Beispielhafte Schreibweisen: . UZH - Methodenberatung - Datenanalyse. MADlib: Main Page. Ten Machine Learning Algorithms You Should Know to Become a Data Scientist.
Top 10 Data Mining Algorithms, Explained.
Faktorenanalyse. FP-Growth-Algorithm. Apriori. Arules: Association Rule Mining with R — A Tutorial. U05 Slides. Teaching - Machine Learning Group - University of Potsdam. Regression - Einführung. Author: Hans Lohninger In der Datenanalyse kommt es häufig vor, dass Daten über unbekannte Proben erhoben werden, die einen Zusammenhang zwischen den gemessenen Variablen aufweisen.
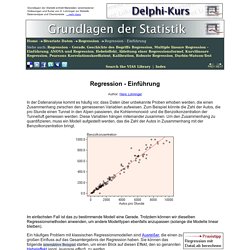
Zum Beispiel könnte die Zahl der Autos, die pro Stunde einen Tunnel in den Alpen passieren, die Kohlenmonoxid- und die Benzolkonzentration der Tunnelluft gemessen werden. Diese Variablen hängen miteinander zusammen. Um den Zusammenhang zu quantifizieren, muss ein Modell aufgestellt werden, das die Zahl der Autos in Zusammenhang mit der Benzolkonzentration bringt. Im einfachsten Fall ist das zu bestimmende Modell eine Gerade. Ein häufiges Problem mit klassischen Regressionsmodellen sind Ausreißer, die einen zu großen Einfluss auf das Gesamtergebnis der Regression haben. Frequent Itemset Suche.
Markoff Kette. Vectors.