
Www.frontiersincomputervision.com/slides/FCV_Core_Szeliski_Zisserman.pdf. CVonline - Compendium of Computer Vision. Overview CVonline is a resource for computer vision, machine vision, image analysis and some visual psychophysics and visual neurophysiology.
The main elements are: Because of the improvements in the content available in Wikipedia, it is now possible to find about 1000 of the 2000 topics in CVonline. Topic Hierarchy in GoogleSites that index Wikipedia pages Wikipedia general topic pages Non-Wikipedia CVonline resources Additional Vision Educational Resources Editing CVonline Topic Hierarchy We had originally tried to create the hierarchy of CVonline inside Wikipedia so that the community could edit the structure. Administration We gratefully thank all of the contributors. Comments and suggestions to: , who is really Bob Fisher. Other CV Online Sites Please note that there are other "CV Online" sites, including: An employment services site in Hungary There have been. The Curse of Dimensionality in Classification. Introduction In this article, we will discuss the so called ‘Curse of Dimensionality’, and explain why it is important when designing a classifier.
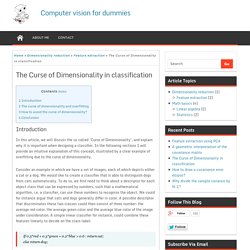
In the following sections I will provide an intuitive explanation of this concept, illustrated by a clear example of overfitting due to the curse of dimensionality. Consider an example in which we have a set of images, each of which depicts either a cat or a dog. We would like to create a classifier that is able to distinguish dogs from cats automatically. To do so, we first need to think about a descriptor for each object class that can be expressed by numbers, such that a mathematical algorithm, i.e. a classifier, can use these numbers to recognize the object. If 0.5*red + 0.3*green + 0.2*blue > 0.6 : return cat; else return dog; However, these three color-describing numbers, called features, will obviously not suffice to obtain a perfect classification. Figure 1. The curse of dimensionality and overfitting. Computer vision for dummies - A blog about intelligent algorithms, machine learning, computer vision, datamining and more.
Computer Vision Expert Blog » Papers. Marcos Nieto's Blog. What is segmentation-driven object recognition? In this post, I want to discuss what the term "segmentation-driven object recognition" means to me.
While segmentation-only and object recognition-only research papers are ubiquitous in vision conferences (such as CVPR , ICCV, and ECCV), a new research direction which uses segmentation for recognition has emerged. Many researchers pushing in this direction are direct descendants of the great J. Malik such as Belongie, Efros, Mori, and many others.
The best example of segmentation-driven recognition can be found in Rabinovich's Objects in Context paper. The basic idea in this paper is to compute multiple stable segmentations of an input image using Ncuts and use a dense probabilistic graphical model over segments (combining local terms and segment-segment context) to recognize objects inside those regions. 7 Advances Pushing the Boundaries of Computer Vision. Before we can think critically about computer vision, we need to take a moment to appreciate our own human vision system.

Just think what we have been able to do in our lives as humans with eyeballs! We have analyzed, sorted, made sense of arbitrary objects in arbitrary situations, effortlessly tracked the movement of things, recalled perfect 3D models of images, read (written, typed, or even illustrated) letters, numbers, and words, and since we were born, recognized thousands of faces. Our ability to organize and comprehend the masses of information that comes to our eyes each day is nothing short of amazing. For computers, however, the life behind their camera lenses and other sensors (i.e., artificial intelligence) has been less than amazing and more fraught with confusion. However, this is all now changing for the better.
Why the wait? Here are 7 recent advances that should grab your attention: 1. 2. But dog species identification is just the beginning. VisionWang: Computer Vision Expert Blog. Computer Vision Talks. The Serious Computer Vision Blog. By Li Yang Ku (Gooly) A few years ago while I was still back in UCLA, Tomaso Poggio came to give a talk about the object recognition work he did with 2D templates.

After the talk some student asked about whether he thought about using a 3D model to help recognizing objects from different viewpoints. “The field seems to agree that models are stored as 2D images instead of 3D models in human brain” was the short answer Tomaso replied. Since then I took it as a fact and never had a second thought of it till a few month ago when I actually need to argue against storing a 3D model to people in robotics.
To get the full story we have to first go back to the late 70s. The structural description model or object centered theory was the dominant theory of visual object understanding around that time and it can correctly predict the view-independent recognition of familiar objects. Paper clip like objects used in Bulthoff’s experiments Viewpoint specific neurons References not linked in post: