
Synthese_vocale. La synthèse vocale (ou TTS, pour Text To Speech) consiste à transformer un texte en suite de sons se rapprochant autant que possible de la parole humaine.
Une des applications les plus évidentes de la synthèse vocale est l'accessibilité pour les mal-voyants. Il existe plusieurs synthétiseurs vocaux sous Linux, cette page ne se veut pas exhaustive. La synthèse vocale procède en trois temps : Prosodie (ajout d'informations de prononciation : accents toniques, indication de durée, etc.) ; assembler des sons pré-enregistrés en suivant les règles établies par les deux premières étapes. Synthèse vocale sous linux. Synthèse vocale. Stephen Hawking était l'une des personnes les plus connues utilisant ce genre de technique pour communiquer.
La synthèse vocale est une technique informatique de synthèse sonore qui permet de créer de la parole artificielle à partir de n'importe quel texte. Pour obtenir ce résultat, elle s'appuie à la fois sur des techniques de traitement linguistique, notamment pour transformer le texte orthographique en une version phonétique prononçable sans ambiguïté, et sur des techniques de traitement du signal pour transformer cette version phonétique en son numérisé écoutable sur un haut parleur. Il s'agit, comme la reconnaissance vocale, d'une technologie permettant de construire des interfaces vocales. Historique[modifier | modifier le code] Les enjeux de la synthèse vocale sont posés en 1761 par le grand mathémacien Leonhardt Euler : "La construction d'une machine propre à exprimer tous les sons de nos paroles, avec toutes les articulations, seroit sans-doute une découverte bien importante.
Svoxpico. Les anciens moteurs de synthèse vocale sous Linux sont vieillissants et loin d'être à la hauteur de ceux présents dans les autres systèmes d'exploitation.
Dans ce domaine, Android a apporté un peu de fraîcheur avec l'apparition du moteur picoTTS. PicoTTS a été créé par SVOX puis racheté par Nuance qui a plus ou moins abandonné le projet, certainement pour ne pas concurrencer son moteur TTS payant. Google, qui l'a choisi comme moteur de synthèse vocale (Text To Speech) pour Android 1.6 en 2009, continue de le développer sur son Dépôt GIT. Ce système a la particularité d'être le plus fluide des solutions disponibles sous Linux et d'être multilingue. Voici les langues supportées: Anglais en-US Français fr-FR Espagnol es-ES Allemand de-DE Italien it-IT Disposer d'une connexion à Internet configurée et activée.
Interface Graphique gSpeech Par défaut, Svoxpico s'utilise en ligne de commande. Lancement de Gspeech 0.8. Bonjour à tous.
J'ai décidé de dépoussiérer un logiciel qui me semblait avoir un bon potentiel mais quelques lacunes. gSpeech est un petit utilitaire qui permet de lire du texte. (synthèse vocale) Pour un descriptif détaillé : et pour un complément d'information : Bon, on peut pas dire que le TTS (Text To Speech) soit la joie sous Linux. Ça fait maintenant quelques années que j'aide au développement de la distribution Primtux et gSpeech (ainsi que la lib pico Vox) est au cœur de la synthèse vocale. Gspeech [PrimTux - Wiki] Commande picoTTS. eSpeak. eSpeak: Speech Synthesizer. Espeak. eSpeak, écrit en C++, est un logiciel de synthèse vocale pour l'anglais et certaines autres langues, dont le français.
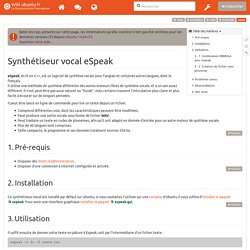
Il utilise une méthode de synthèse différente des autres moteurs libres de synthèse vocale, et a un son assez différent. Il n'est peut-être pas aussi naturel ou "fluide", mais certains trouvent l'articulation plus claire et plus facile à écouter sur de longues périodes. Il peut être lancé en ligne de commande pour lire un texte depuis un fichier. Comprend différentes voix, dont les caractéristiques peuvent être modifiées. Peut produire une sortie vocale sous forme de fichier WAV. Disposer d'une connexion à Internet configurée et activée. Il suffit ensuite de donner votre texte en pâture à Espeak, soit par l'intermédiaire d'un fichier texte : MBROLA.
MBROLA is speech synthesis software as a worldwide collaborative project.
The MBROLA project web page provides diphone databases for many[1] spoken languages. The MBROLA software is not a complete speech synthesis system for all those languages; the text must first be transformed into phoneme and prosodic information in MBROLA's format, and separate software (e.g. eSpeakNG) is necessary. History[edit] MBROLA project started in 1995 at TCTS Lab of the Faculté polytechnique de Mons (Belgium) as a scientific project to obtain a set of speech synthesizers for as many languages as possible.
First release of mbrola software was in 1996 and was provided as freeware for non-commercial, non-military application.[2] Licenses for created voice databases differ, but are also mostly for non-commercial and non-military use. Used technology[edit] MBROLA is a time-domain algorithm similar to PSOLA, which implies very low computational load at synthesis time. References[edit] See also[edit] Synthese_vocale mbrola. Gespeaker. Gespeaker est une interface graphique pour le synthétiseur vocal eSpeak, similaire à eSpeaker mais pour l’environnement de bureau Gnome.
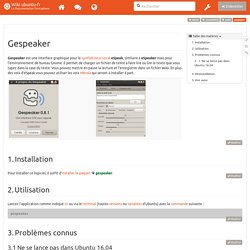
Il permet de charger un fichier de texte à faire lire ou lire le texte que vous tapez dans la case du texte. Commande. Commande avec mbrola. Festival Speech Synthesis System. Un article de Wikipédia, l'encyclopédie libre.
Festival est un logiciel de synthèse vocale développé au centre pour la recherche de technologie de la parole (CSTR) à l'université d'Édimbourg. Festival est écrit dans le langage C++ avec un interpréteur de commandes basé sur Scheme pour permettre sa personnalisation et son évolution. Festival est équipé d'une bibliothèque pour la manipulation des différents objets durant le traitement du texte jusqu’à la production de la parole synthétisée, cette bibliothèque est : Edinburgh Speech Tools Library. Le projet de Festvox vise à créer de nouvelles voix synthétiques, permettant son utilisation par n'importe qui.