
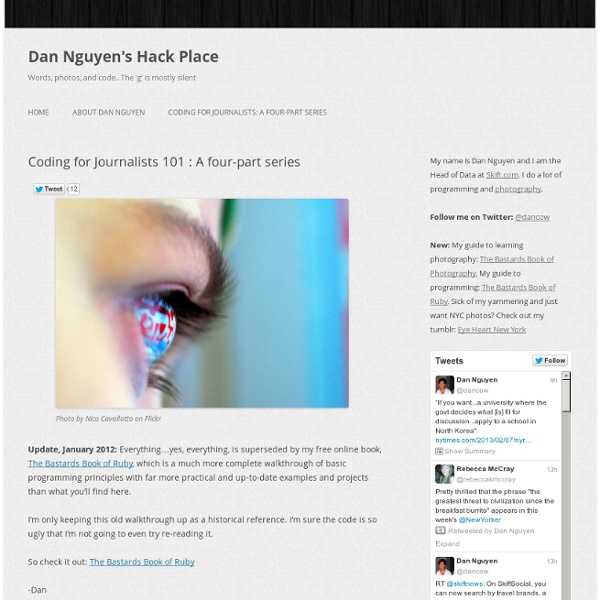
Ruby Programming Language Data Scraping Wikipedia with Google Spreadsheets Prompted in part by a presentation I have to give tomorrow as an OU eLearning community session (I hope some folks turn up – the 90 minute session on Mashing Up the PLE – RSS edition is the only reason I’m going in…), and in part by Scott Leslie’s compelling programme for a similar duration Mashing Up your own PLE session (scene scetting here: Hunting the Wily “PLE”), I started having a tinker with using Google spreadsheets as for data table screenscraping. So here’s a quick summary of (part of) what I found I could do. The Google spreadsheet function =importHTML(“”,”table”,N) will scrape a table from an HTML web page into a Google spreadsheet. The URL of the target web page, and the target table element both need to be in double quotes. The number N identifies the N’th table in the page (counting starts at 0) as the target table for data scraping. Grab the URL, fire up a new Google spreadsheet, and satrt to enter the formula “=importHTML” into one of the cells: Why CSV? Lurvely… :-)
An Introduction to Compassionate Screen Scraping Screen scraping is the art of programatically extracting data from websites. If you think it's useful: it is. If you think it's difficult: it isn't. We're going to be doing this tutorial in Python, and will use the httplib2 and BeautifulSoup libraries to make things as easy as possible. Websites crash. For my blog, the error reports I get are all generated by overzealous webcrawlers from search engines (perhaps the most ubiquitous specie of screenscraper). This brings us to my single rule for socially responsible screen scraping: screen scraper traffic should be indistinguishable from human traffic. Cache feverently. Now, armed with those three guidelines, lets get started screen scraping. Setup Libraries First we need to install the httplib2 and BeautifulSoup libraries. sudo easy_install BeautifulSoup sudo easy_install httplib2 If you don't have easy_install installed, then you'll need to download them from their project pages at httplib2 and BeautifulSoup. Choosing a Scraping Target
Beautiful Soup: We called him Tortoise because he taught us. [ Download | Documentation | Hall of Fame | For enterprise | Source | Changelog | Discussion group | Zine ] You didn't write that awful page. You're just trying to get some data out of it. Beautiful Soup is here to help. Beautiful Soup is a Python library designed for quick turnaround projects like screen-scraping. Beautiful Soup provides a few simple methods and Pythonic idioms for navigating, searching, and modifying a parse tree: a toolkit for dissecting a document and extracting what you need. Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. Valuable data that was once locked up in poorly-designed websites is now within your reach. Interested? Getting and giving support If you have questions, send them to the discussion group. If you use Beautiful Soup as part of your work, please consider a Tidelift subscription. Download Beautiful Soup The current release is Beautiful Soup 4.9.1 (May 17, 2020). Beautiful Soup 3 Hall of Fame Development
Python Programming Language – Official Website Creating a Scraper for Multiple URLs Using Regular Expressions | OutWit Technologies Blog Important Note: The tutorials you will find on this blog may become outdated with new versions of the program. We have now added a series of built-in tutorials in the application which are accessible from the Help menu.You should run these to discover the Hub. NOTE: This tutorial was created using version 0.8.2. In this example we’ll redo the scraper from the previous lesson using Regular Expressions. Recap: For complex web pages or specific needs, when the automatic data extraction functions (table, list, guess) don’t provide you with exactly what you are looking for, you can extract data manually by creating your own scraper. First, Launch OutWit Hub then open in the Page view: In the page view you will see a list of leading firms by activity. Traditionally, you’d have to click on each link, then copy and paste the information into an excel spreadsheet, but with the scraper function we’re going to save a lot of time and energy.
Branded journalists battle newsroom regulations With social media a big part of newsroom life, individual journalists often find their personal brands attractive selling points for future employers. But lately many of these same social media superstars are questioning whether newsrooms are truly ready for the branded journalist. In late January, Matthew Keys, Deputy Social Media Editor at Reuters, wrote a blog post in which he criticized his former employer (ABC affiliate KGO-TV in San Francisco) for taking issue with his use of social media. Keys says his supervisors questioned the language, tone and frequency of his tweets, as well as his judgment when he retweeted his competitors. Not long after Keys’ post went live, CNN’s Roland Martin was suspended for comments he tweeted during the Super Bowl. Then came the news that Britain’s Sky News had revised its social media policies that forbid, among other things, retweeting Sky competitors. NPR’s media correspondent David Folkenflik has a thriving social media presence. Employers:
IRobotSoft -- Visual Web Scraping and Web Automation Tool for FREE Automated Form Submissions and Data Scraping - MySQL Hello Everyone! I'm working on a project that should help me to automate some processes that are extremely time dependent, with a mySQL database. I'm presently working with 2 developers on this project on a contract basis to complete the job. I'm finding my developer hesitant to come up with a solution on how to possibly implement what I'm requesting be done. Therefore, I'm wondering if it can be done at all. I use an online web application to host my data. All of the merchant's gift card services I use have a platform where you can check card balances. The above link is a page where you can check card balances. I would like the mySQL database or another application if its more suited to have the following happen: I would like to repeat a similar task on a few other balance checking pages as well. Any ideas on if this is possible?
OutWit Hub Development of an automated climatic data scraping, filtering and display system 10.1016/j.compag.2009.12.006 : Computers and Electronics in Agriculture Abstract One of the many challenges facing scientists who conduct simulation and analysis of biological systems is the ability to dynamically access spatially referenced climatic, soil and cropland data. Over the past several years, we have developed an Integrated Agricultural Information and Management System (iAIMS), which consists of foundation class climatic, soil and cropland databases. These databases serve as a foundation to develop applications that address different aspects of cropping systems performance and management. Climatic data are usually available via web pages or FTP sites. Three types of data are stored in the process: original climatic data in file format, parsed climatic data in SQL Server database, and filtered climatic data in SQL Server database. Keywords Climatic data; Web scraping; Data fetching; Data parsing; Data filtering; Data exploring; Temporal interpolation; Spatial interpolation; Missing data estimation Copyright © 2009 Elsevier B.V.