
http://en.wikipedia.org/wiki/Machine_learning
Artificial Intelligence and Machine Learning A Gaussian Mixture Model Layer Jointly Optimized with Discriminative Features within A Deep Neural Network Architecture Ehsan Variani, Erik McDermott, Georg Heigold ICASSP, IEEE (2015) Adaptation algorithm and theory based on generalized discrepancy Corinna Cortes, Mehryar Mohri, Andrés Muñoz Medina Proceedings of the 21st ACM Conference on Knowledge Discovery and Data Mining (KDD 2015) Adding Third-Party Authentication to Open edX: A Case Study John Cox, Pavel Simakov Proceedings of the Second (2015) ACM Conference on Learning @ Scale, ACM, New York, NY, USA, pp. 277-280 An Exploration of Parameter Redundancy in Deep Networks with Circulant Projections Yu Cheng, Felix X.
Genetic algorithm The 2006 NASA ST5 spacecraft antenna. This complicated shape was found by an evolutionary computer design program to create the best radiation pattern. Genetic algorithms find application in bioinformatics, phylogenetics, computational science, engineering, economics, chemistry, manufacturing, mathematics, physics, pharmacometrics and other fields. Conservative Myths and the Death of Marlboro Man Those of a certain age remember TV ads featuring the Marlboro Man – a rugged individual who rode a horse through an America that even then had long since disappeared. He was self-reliant. No moocher. Didn’t need government handouts. Didn’t need government. What he needed was cigarettes.
Science Systematic enterprise that builds and organizes knowledge The Universe represented as multiple disk-shaped slices across time, which passes from left to right Modern science is typically divided into three major branches that consist of the natural sciences (e.g., biology, chemistry, and physics), which study nature in the broadest sense; the social sciences (e.g., economics, psychology, and sociology), which study individuals and societies; and the formal sciences (e.g., logic, mathematics, and theoretical computer science), which study abstract concepts. There is disagreement,[19][20][21] however, on whether the formal sciences actually constitute a science as they do not rely on empirical evidence.[22][20] Disciplines that use existing scientific knowledge for practical purposes, such as engineering and medicine, are described as applied sciences.[23][24][25][26]
Cluster analysis Task of grouping a set of objects so that objects in the same group (or cluster) are more similar to each other than to those in other clusters The result of a cluster analysis shown as the coloring of the squares into three clusters. Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters). It is a main task of exploratory data mining, and a common technique for statistical data analysis, used in many fields, including machine learning, pattern recognition, image analysis, information retrieval, bioinformatics, data compression, and computer graphics. Besides the term clustering, there are a number of terms with similar meanings, including automatic classification, numerical taxonomy, botryology (from Greek βότρυς "grape"), typological analysis, and community detection. Definition[edit]
Gaussian Processes for Machine Learning: Contents Carl Edward Rasmussen and Christopher K. I. Williams MIT Press, 2006. ISBN-10 0-262-18253-X, ISBN-13 978-0-262-18253-9. This book is © Copyright 2006 by Massachusetts Institute of Technology. Applying machine learning or bio-inspired learning techniques to communication networks: Firestation <p class="box warning">JavaScript is disabled in your browser. Please enable to use all features of this website.</p> Music Tech Fest 2013: the Festival of Music Ideas Invalid quantity. Please enter a quantity of 1 or more. The quantity you chose exceeds the quantity available.
Computer science Computer science deals with the theoretical foundations of information and computation, together with practical techniques for the implementation and application of these foundations History[edit] The earliest foundations of what would become computer science predate the invention of the modern digital computer. Machines for calculating fixed numerical tasks such as the abacus have existed since antiquity, aiding in computations such as multiplication and division.
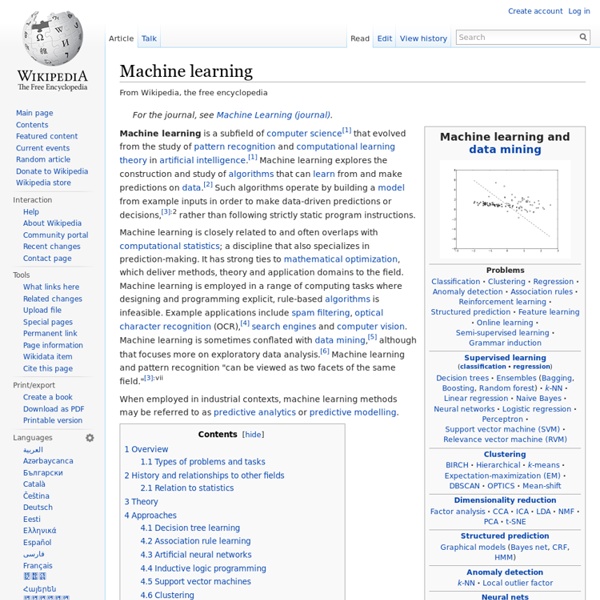
Data mining Data mining is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.[1] Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information (with intelligent methods) from a data set and transform the information into a comprehensible structure for further use.[1][2][3][4] Data mining is the analysis step of the "knowledge discovery in databases" process or KDD.[5] Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.[1] Etymology[edit] In the 1960s, statisticians and economists used terms like data fishing or data dredging to refer to what they considered the bad practice of analyzing data without an a-priori hypothesis.
Gaussian Processes for Machine Learning: Book webpage Carl Edward Rasmussen and Christopher K. I. Williams The MIT Press, 2006. Dark Internet Causes[edit] Failures within the allocation of Internet resources due to the Internet's chaotic tendencies of growth and decay are a leading cause of dark address formation. One form of dark address is military sites on the archaic MILNET. These government networks are sometimes as old as the original ARPANET, and have simply not been incorporated into the Internet's evolving architecture. See also[edit] References[edit]