
EEML Web search engine Software system for finding relevant information on the Web A search engine is a software system that provides hyperlinks to web pages and other relevant information on the Web in response to a user's query. The user inputs a query within a web browser or a mobile app, and the search results are often a list of hyperlinks, accompanied by textual summaries and images. Users also have the option of limiting the search to a specific type of results, such as images, videos, or news. For a search provider, its engine is part of a distributed computing system that can encompass many data centers throughout the world. There have been many search engines since the dawn of the Web in the 1990s, but Google Search became the dominant one in the 2000s and has remained so. In 1945, Vannevar Bush described an information retrieval system that would allow a user to access a great expanse of information, all at a single desk.[3] He called it a memex. 1990s: Birth of search engines [edit] By 2000, Yahoo!
OAuth This article applies to OAuth 1.0 and 1.0a. Your mileage will vary when using OAuth 1.1 or 2.0. One of the projects I’ve been working on instead of updating this blog has been a set of modules for Drupal that allow FriendFeed users do all sorts of interesting things. While I’m not ready to release the details of those projects, one of the biggest mind-benders I’ve experienced in my work has been OAuth, a technology FriendFeed uses as its preferred authentication mechanism in the latest version of its API. It took me a while to figure out how exactly OAuth works: either the information on the web is very bare, or I’m just very dense. One can easily get overwhelmed with all the stuff you have to do when using OAuth, so I’m going to present the workflow several times, starting with a very high level overview. This guide should be helpful for any OAuth scenario, but for explanation’s sake, I’m going to use the following terminology conventions: The 100,000-foot View: Basics So far so good.
Comet (programming) Comet is a web application model in which a long-held HTTP request allows a web server to push data to a browser, without the browser explicitly requesting it.[1][2] Comet is an umbrella term, encompassing multiple techniques for achieving this interaction. All these methods rely on features included by default in browsers, such as JavaScript, rather than on non-default plugins. The Comet approach differs from the original model of the web, in which a browser requests a complete web page at a time.[3] The use of Comet techniques in web development predates the use of the word Comet as a neologism for the collective techniques. The ability to embed Java applets into browsers (starting with Netscape 2.0 in March 1996[10]) made real-time communications possible, using a raw TCP socket[11] to communicate between the browser and the server. Even if not yet known by that name, the very first Comet implementations date back to 2000,[18] with the Pushlets, Lightstreamer, and KnowNow projects.
Web scraping Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.[1] Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis. Web scraping a web page involves fetching it and extracting from it.[1][2] Fetching is the downloading of a page (which a browser does when you view the page). Newer forms of web scraping involve listening to data feeds from web servers. There are methods that some websites use to prevent web scraping, such as detecting and disallowing bots from crawling (viewing) their pages. History[edit] Techniques[edit] Human copy-and-paste[edit]
WCF Windows Communication Foundation (WCF) is a framework for building service-oriented applications. Using WCF, you can send data as asynchronous messages from one service endpoint to another. A service endpoint can be part of a continuously available service hosted by IIS, or it can be a service hosted in an application. A secure service to process business transactions. While creating such applications was possible prior to the existence of WCF, WCF makes the development of endpoints easier than ever. WCF is a flexible platform. The first technology to pair with WCF was the Windows Workflow Foundation (WF). Microsoft BizTalk Server R2 also utilizes WCF as a communication technology. Microsoft Silverlight is a platform for creating interoperable, rich Web applications that allow developers to create media-intensive Web sites (such as streaming video). Microsoft .NET Services is a cloud computing initiative that uses WCF for building Internet-enabled applications. Reference Concepts
Microformats Web science From Wikipedia, the free encyclopedia Emerging interdisciplinary field Web science is an emerging interdisciplinary field concerned with the study of large-scale socio-technical systems, particularly the World Wide Web.[1][2] It considers the relationship between people and technology, the ways that society and technology co-constitute one another and the impact of this co-constitution on broader society. An earlier definition was given by American computer scientist Ben Shneiderman: "Web Science" is processing the information available on the web in similar terms to those applied to natural environment.[4] The Web Science Institute describes Web Science as focusing "the analytical power of researchers from disciplines as diverse as mathematics, sociology, economics, psychology, law and computer science to understand and explain the Web. Areas of activity[edit] Emergent properties[edit] Research groups[edit] Related major conferences[edit] See also[edit] References[edit] External links[edit]
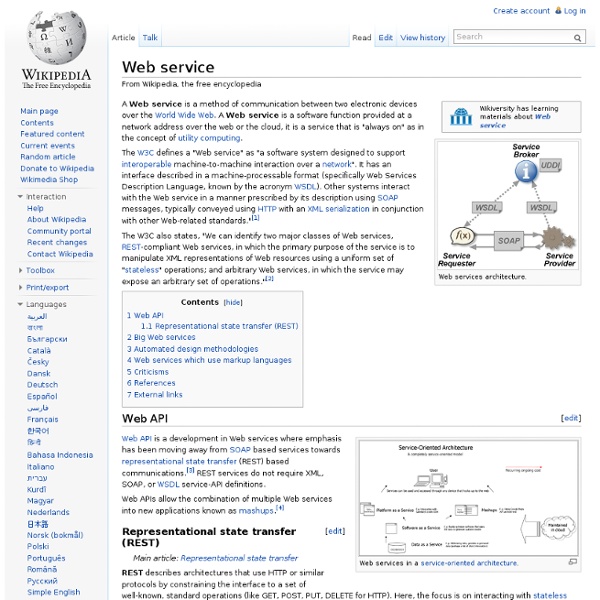
Restful Representational State Transfer (REST) is a software architecture style consisting of guidelines and best practices for creating scalable web services.[1][2] REST is a coordinated set of constraints applied to the design of components in a distributed hypermedia system that can lead to a more performant and maintainable architecture.[3] REST has gained widespread acceptance across the Web[citation needed] as a simpler alternative to SOAP and WSDL-based Web services. RESTful systems typically, but not always, communicate over the Hypertext Transfer Protocol with the same HTTP verbs (GET, POST, PUT, DELETE, etc.) used by web browsers to retrieve web pages and send data to remote servers.[3] The REST architectural style was developed by W3C Technical Architecture Group (TAG) in parallel with HTTP 1.1, based on the existing design of HTTP 1.0.[4] The World Wide Web represents the largest implementation of a system conforming to the REST architectural style. Architectural properties[edit]
HTML WebSockets WebSocket is a protocol providing full-duplex communications channels over a single TCP connection. The WebSocket protocol was standardized by the IETF as RFC 6455 in 2011, and the WebSocket API in Web IDL is being standardized by the W3C. Technical overview[edit] Browser implementation[edit] WebSocket protocol handshake[edit] To establish a WebSocket connection, the client sends a WebSocket handshake request, for which the server returns a WebSocket handshake response, as shown in the following example:[9]:section 1.2 Client request: GET /chat HTTP/1.1 Host: server.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw== Sec-WebSocket-Protocol: chat, superchat Sec-WebSocket-Version: 13 Origin: Server response: HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk= Sec-WebSocket-Protocol: chat Note that each line ends with an EOL (end of line) sequence, \r\n.
Web literacy From Wikipedia, the free encyclopedia Ability to produce, consume or evaluate web content. Web literacy refers to the skills and competencies needed for reading, writing, and participating on the web.[1] It has been described as "both content and activity" meaning that web users should not just learn about the web but also about how to make their own website.[2] History of the concept[edit] In the late 1990s, literacy researchers began to explore the differences between printed text and network-enabled devices with screens. Web Literacy Map[edit] Literacy Version 1.1 of the Web Literacy Map was released in early 2014[10] and underpins the Mozilla Foundation's Webmaker resources section, where learners and mentors can find activities that help teach related areas. The Mozilla community finalized version 1.5 of the Web Literacy Map at the end of March 2015.[11] This involves small changes to the competencies layer and a comprehensive review of the skills they contain.[12] Exploring[edit]
Constrained Application Protocol (CoAP) CoRE Working Group Z. Shelby Internet-Draft Sensinode Intended status: Standards Track K. Hartke Expires: December 30, 2013 C. [include full document text] Web intelligence From Wikipedia, the free encyclopedia Web intelligence is the area of scientific research and development that explores the roles and makes use of artificial intelligence and information technology for new products, services and frameworks that are empowered by the World Wide Web.[1] The term was coined in a paper written by Ning Zhong, Jiming Liu Yao and Y.Y. Ohsuga in the Computer Software and Applications Conference in 2000.[2] The research about the web intelligence covers many fields – including data mining (in particular web mining), information retrieval, pattern recognition, predictive analytics, the semantic web, web data warehousing – typically with a focus on web personalization and adaptive websites.[3]
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
2025-08-03 20:42
by raviii Aug 3
Web Service: A software component created with an interface consisting of a WSDL definition, an XML schema definition, and a WS-Policy definition. Collectively, components could be called a service contract — or, alternatively, an API. See also API, WSDL (Web Standard Definition Language), WS (Web Standard), and XML (eXtended Markup Language).
Found in: Hurwitz, J., Nugent, A., Halper, F. & Kaufman, M. (2013) Big Data For Dummies. Hoboken, New Jersey, United States of America: For Dummies. ISBN: 9781118504222. by raviii Jan 1