Gestion par volumes logiques
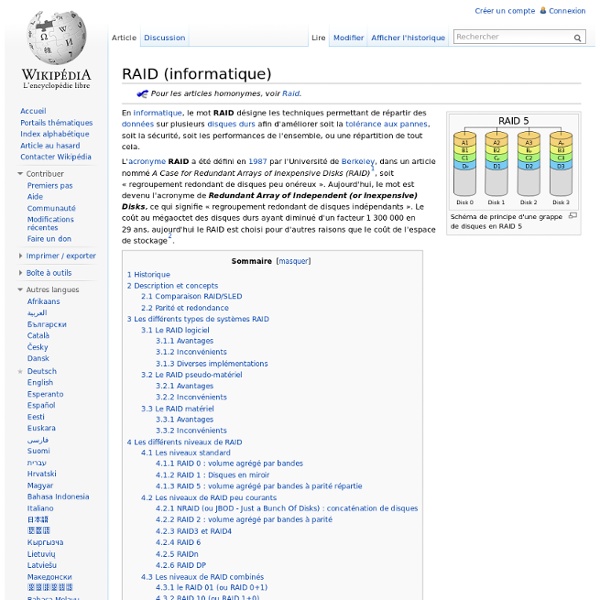
Un article de Wikipédia, l'encyclopédie libre. La gestion par volumes logiques (en anglais, logical volume management ou LVM) est à la fois une méthode et un logiciel de gestion de l'utilisation des espaces de stockage d'un ordinateur. Il permet de gérer, sécuriser et optimiser de manière souple les espaces de stockage en ligne dans les systèmes d'exploitation de type UNIX. On parle également de gestionnaire de volumes ou Volume Manager en anglais. Concepts[modifier | modifier le code] LVM : VG (volume group), PV (physical volume) and LV (logical volume) Volumes physiques PV[modifier | modifier le code] Groupes de volumes VG[modifier | modifier le code] On concatène ces volumes physiques dans des « groupes de volumes » (volume groups ou VG). Volumes logiques LV[modifier | modifier le code] Des « volumes logiques » (logical volumes ou LV) sont alors découpés dans les groupes de volumes, puis formatés et montés dans des systèmes de fichiers ou utilisés en tant que raw devices. Ensuite,
raid et lvm
Sommaire Introduction I. Raid 1. Introduction Performance, disponibilité et coût, voici un résumé de la technologie RAID. Dans ce document, nous verrons, dans un premier temps, les grands principes de cette technologie, nous soulèverons les avantages et inconvénients (et oui, tout n'est pas rose), nous analyserons les différentes moutures qui ont émergées et enfin nous étudierons sa mise en place logicielle dans un système tel que linux. Dans un second temps, nous ferrons le rapprochement avec la technologie logicielle LVM. 1. Le RAID (Redundant Array of Independant Disks ou Redundant Array of Inexpensive Disks) est issu des travaux d'un groupe de chercheurs de l'Université de Berkely en Californie en 1987. Le RAID s'est très vite imposé comme un standard et son domaine d'application s'est considérablement étendu. Mais pourquoi cet intérêt ? L'un des premiers objectifs du RAID est la prévention de perte de données. 2. L'atout : le stripping b. La redondance par copie : shadowing c. 3. b. c.
RAID et LVM : gestionnaires de stockage sous Linux
La création d'un RAIDset peut se faire lors de l'installation, ou plus tard dans la vie de la configuration, avec les outils Disk Druid ou encore fdisk. La première étape consistera, comme toujours, à créer des partitions, mais qui n'auront pas le type 83 (Linux Native), mais le type fd (Linux RAID). Ces partitions seront crées sur les disques préalablement sélectionnés, et ne pourront pas être associées à un point de montage : il faut en effet préalablement créer le périphérique RAID (RAID device), qui sera le seul périphérique visible du niveau utilisateur, et qui possédera quand à lui le point de montage. Lors de la création du périphérique RAID, on spécifiera donc le point de montage, le niveau de RAID souhaité (0, 1 ou 5), le nom de périphérique RAID (8 au maximum), de md0 à md7, et le type de partition : Linux Native (83).
LVM : Logical Volume Manager
Tout système de fichiers est habituellement dépendant de contraintes matérielles. Vous pouvez partitionner vos disques en partitions primaires et étendues (avec "lecteurs" logiques) mais ce, à condition de rester dans les limites imparties par la taille de ces disques. LVM permet de dépasser ce stade et de pousser plus loin encore la notion de volumes logiques. Le Logical Volume Manager est un sous-système pour la gestion du stockage des données sur les disques. L'idée de gestion de volumes logiques n'est pas nouvelle. Installation LVM se compose de deux éléments, une partie devant être intégrée au noyau et une partie utilitaire permettant de manipuler les volumes. gzip -dc lvm-*.*. Puis activer le support LVM dans la configuration (make config/menuconfig/xconfig) dans la section "Block devices". Dernière étape concernant la partie noyau, il vous faut renseigner kmod pour lui permettre de charger correctement lvm.o. alias block-major-58 lvm alias char-major-109 lvm Utilisation Et le monter
cours LVM - Admin-Sys
Voici la signification de quelques abréviations utilisées et définies dans la suite de ce chapitre : PV (Physical Volume) : disque physique VG (Volume Group) : groupe de volumes LV (Logical Volume) : volume logique PE (Physical Extend) : extension physique LE (Logical Extend) : extension logique FS (File Sytem) : système de fichier Introduction L’objectif du LVM est de simplifier la gestion de l’espace disque pour l’administrateur, et de s’affranchir d’un certain nombre de contraintes imposées par l’utilisation « classique » des disques. Dans une configuration classique, les disques physiques sont découpés en partitions (on parle aussi de sections), chacune d’elle pouvant soit servir de swap, soit servir de système de fichier (FS) après formatage. De plus, la taille d’une partition quelconque (et donc celle d’un fichier) ne peut excéder la taille d’un disque. Le LVM va nous permettre de gérer de manière beaucoup plus souple l’espace disque, en particulier en permettant (en standard) : Création