
Physics Lecture Demonstrations Compiled and annotated by Donald Simanek The internet has many sources of lecture demonstrations, particularly of demos suitable for large lecture courses. I list just a few. Often the university sites exist primarily for internal use, listing equipment and demos available to physics professors teaching large sections of introductory courses. In my little collection of demos I have included many that are appropriate for smaller classes and classrooms. I'm in the process of improving and refining this document, and intend to include more illustrations, discussion of the underlying physics, and presentation suggestions. How and why to present demonstrations Over the years since Newton, physics teachers have developed a vast catalog of physics lecture demonstrations, which fill many books.Too often these demo books merely describe the demonstration, but don't explain the physics behind it, nor suggest effective ways to present it. Practice the demonstration until you have it perfected.
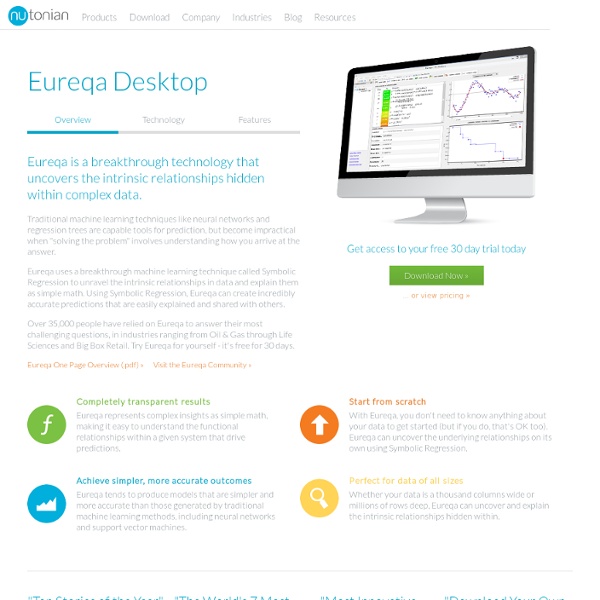
Distilling Free-Form Natural Laws from Experimental Data Michael Schmidt and Hod Lipson Citation: Schmidt M., Lipson H. (2009) "Distilling Free-Form Natural Laws from Experimental Data," Science, Vol. 324, no. 5923, pp. 81 - 85. (see supplemental materials) Software: We have released the Eureqa Application that you can use to search your own data for hidden mathematical relationships. Summary: For centuries, scientists have attempted to identify and document analytical laws that underlie physical phenomena in nature. (A) A computer observes the behavior and dynamics of a real system, and (B) collects data using motion tracking cameras and software. Frequently Asked Questions: Click here to see the FAQ about this research Videos: Click here to see all videos Images: Click here to see hi-res images Related Publications: Bongard J., Zykov V., Lipson H. (2006), "Resilient Machines Through Continuous Self-Modeling," Science Vol. 314, no. 5802, pp. 1118 - 1121. Koza, J. Further Reading: Acknowledgments:
Data Mining Image: Detail of sliced visualization of thirty video samples of Downfall remixes. See actual visualization below. As part of my post doctoral research for The Department of Information Science and Media Studies at the University of Bergen, Norway, I am using cultural analytics techniques to analyze YouTube video remixes. My research is done in collaboration with the Software Studies Lab at the University of California, San Diego. The following is an excerpt from an upcoming paper titled, “Modular Complexity and Remix: The Collapse of Time and Space into Search,” to be published in the peer review journal AnthroVision, Vol 1.1. The excerpt below is rather extensive for a blog post, but I find it necessary to share it in order to bring together elements discussed in previous posts on Remix and Cultural Analytics (see part 1 on the Charleston Mix, part 2 on Radiohead’s Lotus Flower, and part 3 on the Downfall parodies). Image: this is a slice visualization of “Mr.
Santa Strawberries These little Santas are almost too cute to eat. But we ate them all anyway. And then made more, and ate them, too. I was sent the inspiration from these about a week ago from a friend, and couldn't wait to make them. The best part is they're SO easy to make that he made about a dozen himself later on for our dessert. I filled the little guys with whipped creamed, but you can use icing, cream cheese, or anything else on hand that may do. Santa Strawberries Recipe Ingredients: 1 dozen strawberries 1 cup whipped cream a handful of chocolate sprinkles Directions: Using a pairing knife, slice the leafy end off each strawberry so they stand up evenly. Using a spoon or a large icing tip, place a large dollop (about 1-2 tsp) of whipped cream on top of the strawberry base. Place two chocolate sprinkles in the Santas "face" for the eyes. You're done!
The R Project for Statistical Computing Reverse Engineering Dynamical Systems Project members: Josh Bongard and Hod Lipson. Please mention both team members when covering this work. Thank you. Bongard J., Lipson H. (2007), “Automated reverse engineering of nonlinear dynamical systems", Proceedings of the National Academy of Science, vol. 104, no. 24, pp. 9943–9948 Complex nonlinear dynamics arise in many fields of science and engineering, but uncovering the underlying differential equations directly from observations poses a challenging task. More Information Related Publications Bongard J., Zykov V., Lipson H. (2006), “Resilient Machines Through Continuous Self-Modeling", Science 314(5802): 1118 - 1121 Adami C., (2006) "What Do Robots Dream Of?" Applications of this concept to other domains: Aquino W., Kouchmeshky B., Bongard J., Lipson H., (2006) "Co-evolutionary algorithm for structural damage identification using minimal physical testing", Int. Software: This project was supported in part by the Keck Future Initiative Grant NAKFI/SIG07.
5 of the Best Free and Open Source Data Mining Software The process of extracting patterns from data is called data mining. It is recognized as an essential tool by modern business since it is able to convert data into business intelligence thus giving an informational edge. At present, it is widely used in profiling practices, like surveillance, marketing, scientific discovery, and fraud detection. There are four kinds of tasks that are normally involve in Data mining: * Classification - the task of generalizing familiar structure to employ to new data* Clustering - the task of finding groups and structures in the data that are in some way or another the same, without using noted structures in the data.* Association rule learning - Looks for relationships between variables.* Regression - Aims to find a function that models the data with the slightest error. For those of you who are looking for some data mining tools, here are five of the best open-source data mining software that you could get for free: Orange RapidMiner Weka JHepWork
25 (more) awesome iPhone tips and tricks This Digital Crave feature story ran in July and was one of our most popular tech stories of the year. Find out what you are missing out on when it comes to making the most of your iPhone. What's the only thing better than 25 ways to master your iPhone ? 25 more. In case you missed our first round-up of 25 assorted iPhone tips and tricks , be sure to read these simple ways you can get more out of your smartphone investment. In the first post we covered everything from how to dry out a wet iPhone and fixing those dang "autocorrect" issues to using the phone cord to take a picture (and why) and making your own ringtone without having to pay your carrier. And now we've got another 25 awesome things to try with your iPhone , many of which you weren't aware of. And hey, if you have any tips of your own to share, be sure to leave them in the Comments section at the bottom — so you can get credit where it's due. Here we go: Manage your camera time : Here's another tip when using the camera.
The Lowly Programmer: Introducing: Marriage Sort Update: I've created a live visualization of this algorithm, so you can see it in action - see Marriage Sort, a Visualization. Two weeks ago, a link showed up on Hacker News on how to (mathematically) select the best wife. Tongue firmly in cheek, of course. The key takeaway from the article is that knowing only the relative rankings of items in a sequence (and assuming you can never go back to a previous one), you can maximize your chances of selecting the maximum one by letting N/e go by and then picking the next one that's better than all those. And thus, Marriage Sort was born. Algorithm The basic idea of this algorithm is to repeatedly choose the maximum element from the first √N - 1 elements of our working set, and then scan to the end looking for elements bigger than it. One pass of the Marriage Sort. This works because, as we have noted from the article linked above, each element bigger than the first √N - 1 is expected to be close to the largest remaining element in the array.