Welcome — 8th International Conference on Peer-to-Peer Computing (P2P'08)
Projects - Australian Renewable Energy Agency
A world-leading prototype of a virtual power plant (VPP) will be created by installing and connecting a large number of solar battery storage systems across 1000 residential and business premises in Adelaide, South Australia, to be managed by a cloud-based Sunverge control system. The batteries will be able to ‘talk’ to each other through a cloud-based platform using smart controls, forming a connected system that will be able to operate as a 5 MW solar power plant. Need The South Australian electricity market is experiencing a number of complex, interrelated challenges with large, synchronous power generators retiring from the market, gas-fired electricity becoming more expensive through rising gas prices, and intermittent, renewable generation comprising a larger share of the energy supply mix. Innovation Benefit
Free Open Source Distributed Micro-blogging
There is plenty to say about Thimbl. Find out why we're doing this and how. So Thimbl, huh? Thimbl is free, open source and distributed micro-blogging. Will Thimbl be an alternative to Twitter? Well, proprietary, centralized platforms like Twitter are exactly what we're trying to illustrate as unneeded. If there can be an alternative to Twitter, a very well funded and positioned corporation, it must be a platform, not simply an alternative service or some clone-ware. That being said, pushing Thimbl as a far as we can is part of the performance. Isn't this just like identi.ca/ostatus.net? The similarity is only superficial, in that we draw upon similarities with web2.0 platforms in how we communicate our use-case. Diaspora, Crabgrass, NoseRub, StatusNet, identi.ca and the rest are just web-apps with some sort of federation bolted-on. Like the classic internet applications, each of Thimbl tiers are themselves distributed, scalable and transparently interoperable with other instances.
Magnetic South: Exploring a future for Christchurch together
National Electricity Market 'not in the best of health': Energy Security Board
The nation's top energy body has called on federal, state and territory governments to push through the National Energy Guarantee to fix the National Electricity Market, saying high electricity prices for business and households were unsustainable. In its first report on the health of the NEM, the Energy Security Board, created after the landmark Finkel Review, said the decade of inaction on climate policy to bring down Australia's carbon emissions had to end, saying politicians had to deliver the NEG early next year. "The policy uncertainty of the last decade has not only delivered insufficient electricity sector emissions reductions, but it has also increased costs in the industry," the new report released on Wednesday said. "This has led to less than optimal outcomes. The report by the ESB - chaired by respected businesswoman Kerry Schott - also took aim at the key energy bodies running the NEM saying current governance of the energy network was playing "catch-up".
CoreOS is Linux for Massive Server Deployments · CoreOS
AEMO looks forward. Where does AEMC look?
Whoever was responsible for picking Audrey Zibelman to be CEO of the Australian Energy Market Operator has probably done more to improve the outlook for decarbonised electricity supply at an efficient price in Australia than just about anyone else. Leadership matters. The AEMO started 2017 facing black marks for its role in the 2016 South Australian blackout and for seeming to have no idea about what to do to improve the electricity reliability and price outlook. The AEMO at that time seemed to walk hand in hand with the Australian Energy Market Commission, which sets the rules of the market that AEMO operates. This was despite the off and sometimes on the record complaints about the perception that the AEMC acted as a wet blanket on reform. The delayed introduction of the five minute settlement is an obvious example. Just a year on, the AEMO goes into 2018 having worked hard to prepare the NEM for the coming Summer and with the first foundations of “the plan” becoming visible.
Chromium Homepage
Tesla big battery shows off its flexibility in final testing
In the final days of testing before the big opening on Friday, the Tesla big battery in South Australia has been showing some of the capabilities that make it such an exciting addition to Australia’s main electricity grid. As this graph above shows, Tesla and the battery’s owner Neoen followed up the testing of its charging and discharging abilities with a display of rapid changes on Wednesday evening to underline the flexibility of the 100MW/129MWh plant. The graph charts the operations of what is known to the market as the Hornsdale Power Reserve (it is located next to Neoen’s Hornsdale wind farm). Presumably, the aim will be to take advantage of quick changes in wholesale prices, or simply to charge up when prices are low and discharge when they are high, and to help meet peak demand (which it did later Thursday, see update below). The battery is also contracted by the government to provide fast-response stability services to the grid.
An open-source distributed database built with love - RethinkDB
Valuing storage: A closer look at the Tucson Electric solar-plus-storage PPA
The power purchase agreement Tucson Electric Power signed with NextEra Energy for an “all-in cost significantly less than $0.045/kWh over 20 years” has become the new benchmark for combining solar power with energy storage, but at least one industry expert says the math is not as simple as it seems. According to Tucson Electric, the 100 MW solar portion of the project came in at under $0.03/kWh, putting the 30 MW, 120 MWh energy storage piece in the ballpark of $0.015/kWh. “Just because you’re being paid 4.5 cents, doesn’t mean the system costs 4.5 cents,” James Lazar, senior advisor at the Regulatory Assistance Project in Olympia, Wash., told Utility Dive in an interview. Lazar assumes the 100 MW solar system in Arizona produces electricity for 10 hours a day and yields 1,000 MWh a day of energy. But the batteries store only 120 MWh or 12% of the solar output. The utility is still paying $0.045/kWh over the life of the contract, but “it is deceptive to call it $0.015/kWh.
ownCloud.org | Your Cloud, Your Data, Your Way!

-------------------------------------------------------------------------------------------------------------------------------------------------------------------
2025-08-03 19:53
by raviii Aug 3
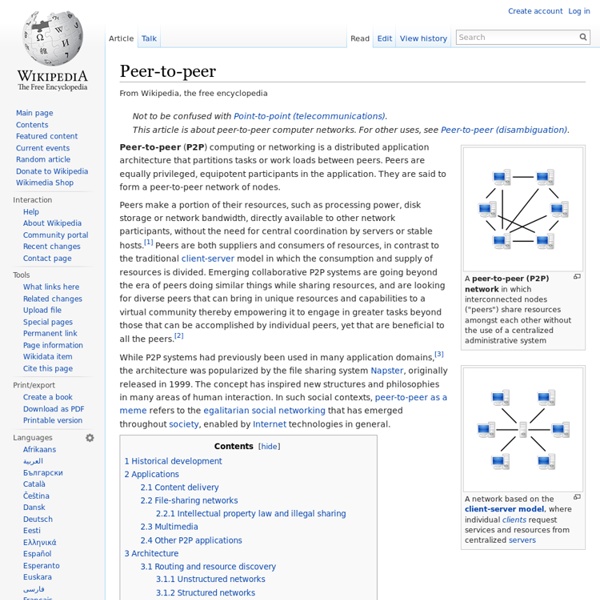
P2P (peer-to-peer): A networking system in which nodes in a network exchange data directly instead of going through a central server.
Found in: Hurwitz, J., Nugent, A., Halper, F. & Kaufman, M. (2013) Big Data For Dummies. Hoboken, New Jersey, United States of America: For Dummies. ISBN: 9781118504222. by raviii Jan 1