
Visualization. Tag cloud. Foundation-l word cloud, created with the complete gzip'ed list archives (without duplicate emails from archives and all headers and quoted text in body), using IBM Word Cloud Generator build 32.[1] A tag cloud with terms related to Web 2.0 History[edit] In the language of visual design, a tag cloud (or word cloud) is one kind of "weighted list", as commonly used on geographic maps to represent the relative size of cities in terms of relative typeface size.
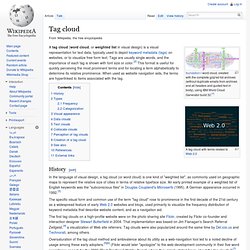
An early printed example of a weighted list of English keywords was the "subconscious files" in Douglas Coupland's Microserfs (1995). A German appearance occurred in 1992.[3] The specific visual form and common use of the term "tag cloud" rose to prominence in the first decade of the 21st century as a widespread feature of early Web 2.0 websites and blogs, used primarily to visualize the frequency distribution of keyword metadata that describe website content, and as a navigation aid. Types[edit] Frequency[edit] Categorization[edit] Visualizing Del.icio.us Roundup. I have been coming across many del.icio.us tools to visualize usage during my daily researching hours.

So many, that I have decided to start making note of the ones I come across. From the span of about two weeks, I have been collecting as many as I could find. I will list each one along with a description. Enjoy! Visualizing the contents of social bookmarking systems. I’ve decided to post a few visualizations I’ve made some time ago as part of my PhD work.

The method has been published, but more as a sidenote [1]; also, I’ve since applied it to additional datasets, so I thought it might be interesting to share those images. In my PhD thesis, I try to make sense of the large bodies of data that are accumulated by people saving resources online, tagging them with whatever words they choose in order to find them later on. Each time a user u saves a document d, using the tags t1, t2, and t3, three triples (d,u,t1), (d,u,t2), (d,u,t3) are created.
Visualizing Social Bookmarks. Semantic Web. The Semantic Web is a collaborative movement led by international standards body the World Wide Web Consortium (W3C).[1] The standard promotes common data formats on the World Wide Web.

By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web, dominated by unstructured and semi-structured documents into a "web of data". The Semantic Web stack builds on the W3C's Resource Description Framework (RDF).[2] According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries".[2] The term was coined by Tim Berners-Lee for a web of data that can be processed by machines.[3]
In Search of Tags Lost: Combining Social Bookmarking and SemWeb Technologies. Executive Summary.

Semantic Grounding of Tag Relatedness. Tag (metadata) The use of keywords as part of an identification and classification system long predates computers.
Paper data storage devices, notably edge-notched cards, that permitted classification and sorting by multiple criteria were already in use prior to the twentieth century, and faceted classification has been used by libraries since the 1930s. Online databases and early websites deployed keyword tags as a way for publishers to help users find content.
The complex dynamics of collaborative tagging. The debate within the Web community over the optimal means by which to organize information often pits formalized classifications against distributed collaborative tagging systems.

Everything is Miscellaneous. Tagging: Five Emerging Trends. Scientific social tagging - background knowledge come to surface (AquaRing Project) Bottom Up Tagging. Tagging That Works - O'Reilly Web 2.0 Expo. Tagging for Collaboration and Knowledge Sharing. Tagging in government institutions. Social bookmarking. Common features[edit] In a social bookmarking system, users save links to web pages that they want to remember and/or share.
These bookmarks are usually public, and can be saved privately, shared only with specified people or groups, shared only inside certain networks, or another combination of public and private domains. The allowed people can usually view these bookmarks chronologically, by category or tags, or via a search engine. Social Bookmarking in the Enterprise at MITRE. The Boston KM Forum topic this evening was Tag Me!

Social Bookmarking in the Enterprise, a talk by Laurie Damianos of MITRE (an interview with her at CMU). Going into the talk, the most interesting thing to me is Laurie's title: she's a Lead Artificial Intelligence Engineer - Can I get that job? Why social bookmarking in the enterprise? MITRE started this project in 2005, when the concept was just blooming from the public web. The problems are familiar: employees at MITRE and elsewhere are having problems capturing, storing and finding references to valuable information. Enterprise Social Bookmarking Pilot - MITRE. Social Media & Learning: Pt 1 Social bookmarking, networking and file sharing. Jane Hart's Articles & Presentations Social Media and Learning Part 1: Social bookmarking, social file-sharing and social networking Inside Learning Technologies Magazine, October 2008 Jane Hart is a Social Media & Learning Consultant who works with organisations to help them understand how new social media tools can be used for learning and performance support.
Nptag - Resources. Analyzing Social Bookmarking Systems. 7 Things... social bookmarking. Taxonomy. From Wikipedia, the free encyclopedia Taxonomy may refer to: Science[edit]
Hybrid Approaches to Taxonomy and Folksonomy 11-20-09. Ontology (information science) In computer science and information science, an ontology formally represents knowledge as a hierarchy of concepts within a domain, using a shared vocabulary to denote the types, properties and interrelationships of those concepts.[1][2] Ontologies are the structural frameworks for organizing information and are used in artificial intelligence, the Semantic Web, systems engineering, software engineering, biomedical informatics, library science, enterprise bookmarking, and information architecture as a form of knowledge representation about the world or some part of it.
The creation of domain ontologies is also fundamental to the definition and use of an enterprise architecture framework. The term ontology has its origin in philosophy and has been applied in many different ways. The word element onto- comes from the Greek ὤν, ὄντος, ("being", "that which is"), present participle of the verb εἰμί ("be"). According to Gruber (1993): Common components of ontologies include: Categories, Links, and Tags. Ontology is Overrated: Categories, Links, and Tags This piece is based on two talks I gave in the spring of 2005 -- one at the O'Reilly ETech conference in March, entitled "Ontology Is Overrated", and one at the IMCExpo in April entitled "Folksonomies & Tags: The rise of user-developed classification.
" The written version is a heavily edited concatenation of those two talks. Folksonomy. An empirical analysis of the complex dynamics of tagging systems, published in 2007,[8] has shown that consensus around stable distributions and shared vocabularies does emerge, even in the absence of a central controlled vocabulary. For content to be searchable, it should be categorized and grouped. While this was believed to require commonly agreed on sets of content describing tags (much like keywords of a journal article), recent research has found that, in large folksonomies, common structures also emerge on the level of categorizations.[9] Accordingly, it is possible to devise mathematical models of collaborative tagging that allow for translating from personal tag vocabularies (personomies) to the vocabulary shared by most users.[10] Origin[edit]
Folksonomy. Vanderwal.net. This page is a static permanent web document. It has been written to provide a place to cite the coinage of folksonomy. This is response the request from many in the academic community to document the circumstances and date of the creation of the term folksonomy. The definition at creation is also part of this document. This document pulls together bits of conversations and ideas I wrote regarding folksonomy on listserves, e-mail, in my blogs and in blog comments on other's sites in 2004. Background I have been a fan of ad hoc labeling and tagging systems since at least the late 1980s after watching a co-worker work his magic with Lotus Magellan (he would add his own ad hoc keywords or tags to the documents on his hard drive, paying particular attention to add these tags to documents others created so to add his context).
Folksonomies: indexing and retrieval ... Classification schemes.