
TensorTalk - Latest AI Code. Brains, Minds and Machines Summer Course 2015. Unsupervised Feature Learning and Deep Learning Tutorial. A 'Brief' History of Neural Nets and Deep Learning, Part 1 – Andrey Kurenkov's Web World. This is the first part of ‘A Brief History of Neural Nets and Deep Learning’.

Part 2 is here, and parts 3 and 4 are here and here. In this part, we shall cover the birth of neural nets with the Perceptron in 1958, the AI Winter of the 70s, and neural nets’ return to popularity with backpropagation in 1986. “Deep Learning waves have lapped at the shores of computational linguistics for several years now, but 2015 seems like the year when the full force of the tsunami hit the major Natural Language Processing (NLP) conferences.” -Dr. Christopher D. Character-Based Deep Convolutional Models. Below are a range of character-based deep convolutional neural networks that are free, even for commercial use in your applications.
These models have been trained over various corpuses, from sentiment analysis in many languages to advertizing link classification from just reading a URL. They should accomodate a range of applications. Training your own models is made easy too and can lead to even more avenues. Tips and tricks for training are included at the bottom of this page. These new models read text at character-level, and have very nice properties: On the other side, these convolutional models: Take often longer to train than BOW modelsRequire large datasets, from several thousands, up to millions of samples In addition to the directly usable models, this page contains information and results from experiments on character-based models. Deep Learning Glossary – WildML. This glossary is work in progress and I am planning to continuously update it.
If you find a mistake or think an important term is missing, please let me know in the comments or via email. Deep Learning terminology can be quite overwhelming to newcomers. This glossary tries to define commonly used terms and link to original references and additional resources to help readers dive deeper into a specific topic. Multilayer Neural Networks. Deeplearning:slides:start. On-Line Material from Other Sources.
Neural networks class - Université de Sherbrooke. Upload Hugo Larochelle Loading...
Working... Very Deep Learning Since 1991 - Fast & Deep / Recurrent Neural Networks. Deeplearn it! www.deeplearning.it (official site) We are currently experiencing a second Neural Network ReNNaissance (title of JS' IJCNN 2011 keynote) - the first one happened in the 1980s and early 90s.

In many applications, our deep NNs are now outperforming all other methods including the theoretically less general and less powerful support vector machines (which for a long time had the upper hand, at least in practice). Check out the, in hindsight, not too optimistic predictions of our RNNaissance workshop at NIPS 2003, and compare the RNN book preface. Some of the (ex-)members of our Deep Learning Team: Sepp Hochreiter, Felix Gers, Alex Graves, Dan Ciresan, Ueli Meier, Jonathan Masci. For medical imaging, we also work with Alessandro Giusti in the group of Luca Maria Gambardella. Another attempt to organize my ML readings .. Hugo Larochelle. GSS2012: Deep Learning, Feature Learning.
Upload.
Publications. Publications Some of the papers are released with code, which comes with a license.

All papers that use GPUs are implemented with gnumpy, which is built on of cudamat Videos of Talks Deep Learning: Theroy and Practice, August 2015 [video] Thinking Machines Podcast: Learning Machines and Magical Thinking, January 2015 [audio] NIPS talk on Sequence to Sequence learning with Neural Networks, December 2014 [video] Talk at the Berkeley Redwood Center, 2014 [video] VLAB deep learning panel, 2014 [video].
Deep Learning Master Class, 2014 [video]. Theses Training Recurrent Neural Networks, Ilya Sutskever, PhD Thesis, 2012. Etc Trans-lingual representation of text documents, John Platt and Ilya Sutskever, Patent #20100324883 Npmat A pure python implementation of cudamat. Deeplearning:slides:start. Home - colah's blog. Understanding Convolutional Neural Networks for NLP. When we hear about Convolutional Neural Network (CNNs), we typically think of Computer Vision.
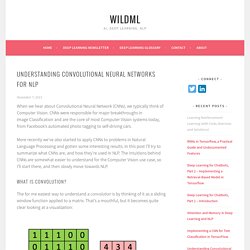
CNNs were responsible for major breakthroughs in Image Classification and are the core of most Computer Vision systems today, from Facebook’s automated photo tagging to self-driving cars. More recently we’ve also started to apply CNNs to problems in Natural Language Processing and gotten some interesting results. In this post I’ll try to summarize what CNNs are, and how they’re used in NLP. The intuitions behind CNNs are somewhat easier to understand for the Computer Vision use case, so I’ll start there, and then slowly move towards NLP. What is Convolution? The for me easiest way to understand a convolution is by thinking of it as a sliding window function applied to a matrix. Convolution with 3×3 Filter. Imagine that the matrix on the left represents an black and white image. You may be wondering wonder what you can actually do with this. The GIMP manual has a few other examples. Narrow vs. . Understanding LSTM Networks. Posted on August 27, 2015 Recurrent Neural Networks Humans don’t start their thinking from scratch every second.

As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking from scratch again. Your thoughts have persistence. Traditional neural networks can’t do this, and it seems like a major shortcoming. GSS2012: Deep Learning, Feature Learning. Kjw0612/awesome-deep-vision. Keras Documentation. Jupyter Notebook Viewer. Gradient descent¶ To train the network, we will minimize the cost (squared Euclidean distance of network output vs. ground-truth) over a training set using gradient descent. When doing gradient descent on neural nets, it's very common to use momentum, which is simply a leaky integrator on the parameter update. That is, when updating parameters, a linear mix of the current gradient update and the previous gradient update is computed. This tends to make the network converge more quickly on a good solution and can help avoid local minima in the cost function.
With traditional gradient descent, we are guaranteed to decrease the cost at each iteration. In Theano, we store the previous parameter update as a shared variable so that its value is preserved across iterations. Goodfeli/theano_exercises. Contents — DeepLearning 0.1 documentation. Representation Learning. I would like to know the answer to question 4 of file finalH12en.pdf especially for the cases (b) and (c) . The most important research papers for deep learning which all machine learning students should definitely read. Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs. Recurrent Neural Networks (RNNs) are popular models that have shown great promise in many NLP tasks.
But despite their recent popularity I’ve only found a limited number of resources that throughly explain how RNNs work, and how to implement them. That’s what this tutorial is about. It’s a multi-part series in which I’m planning to cover the following: As part of the tutorial we will implement a recurrent neural network based language model. The applications of language models are two-fold: First, it allows us to score arbitrary sentences based on how likely they are to occur in the real world. University CS231n: Convolutional Neural Networks for Visual Recognition. The Spring 2020 iteration of the course will be taught virtually for the entire duration of the quarter. (more information available here ) Unless otherwise specified the lectures are Tuesday and Thursday 12pm to 1:20pm.
Discussion sections will (generally) be Fridays 12:30pm to 1:20pm. Check Piazza for any exceptions. Lectures and discussion sections will be both on Zoom, and they will be recorded for later access from Canvas. This is the syllabus for the Spring 2020 iteration of the course. Stanford University CS224d: Deep Learning for Natural Language Processing. Reading List « Deep Learning.