
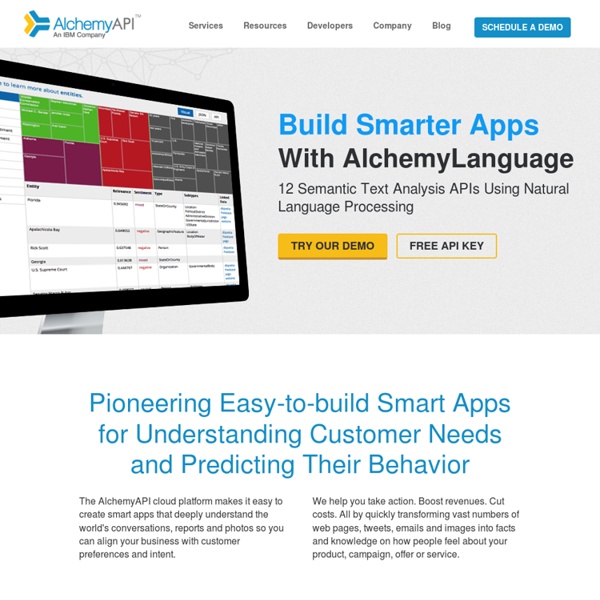
Text Analysis API Saplo API gives you the possibility to build applications upon our text analysis technology platform. Take a look at our Text Analysis API documentation. Through the API you gain access to: Through Saplo API it's possible to automatically extract entities found in text. Inspiration & Ideas: Create theme sites. With Saplo API it is possible to identify how articles are semantically related to each other. Cross link entire websites. Saplo context API gives you the possibility to define personalized textual contexts that are possible to match against any type of text. Firstly, create a context by defining texts that are typically descriptive for the context you aim at creating. Secondly, compare any text to your recently created contexts and Saplo will recognize and rank similar text. Create topic tags such as financial crisis, olympic games or mobile technology.
RelFinder - Visual Data Web Are you interested in how things are related with each other? The RelFinder helps to get an overview: It extracts and visualizes relationships between given objects in RDF data and makes these relationships interactively explorable. Highlighting and filtering features support visual analysis both on a global and detailed level. Check out the following links for some examples: The RelFinder can easily be configured to work with different RDF datasets. The RelFinder can also be more deeply integrated with your project: Integrating the RelFinder See the following examples of how the RelFinder is integrated into other projects: Ontotext applies the RelFinder to enable an exploration of relationships in the biomedical domain. The RelFinder is readily configured to access RDF data of the DBpedia project and only requires a Flash Player plugin to be executed (which is usually already installed in web browsers). All tools on this website are research prototypes that might contain errors.
KerPoof We provide downloadable lesson plans that bring Kerpoof into the classroom, either electronically or through printed scenes and coloring sheets. These lesson plans have been created for a wide range of grades (pre-K and up) and fulfill state and national standards. Check back often for new additions, or sign up for our free newsletter. New! The Three Rs: Reduce, Reuse, and Recycle(grades 1-4) (PDF) Tall Tales: Exploring Fact and Fiction(grades 4-5) (PDF) The Planets(grades 3-6) (PDF) Poetry Partners(grades 2-4) (PDF) Biz Movie Sneak Peek(grades 3-8)Visit the BizWorld Foundation website for more information on the BizMovie curriculum. Lesson Plan (PDF)Worksheet (PDF) Learning to Use Kerpoof These introductory lessons can be adapted to teach any class or audience how to use Kerpoof. Master Artist Series Impressionist Art(grades 4-8) (PDF) M.C. Math and Science Language Arts Social Studies Get Involved! Remember to visit the Classroom Ideas page for more ways to use Kerpoof in the classroom!
Kundenservice auf dem Weg in das Outernet: Willkommen in der Augmented Reality | Blog von Prof. Dr. Heike Simmet i 7 Votes istock Photo Prof. Der Kundenservice in Deutschland befindet sich in einer tiefgreifenden Umbruchphase. Doch die technologische Entwicklung beschleunigt sich zunehmend weiter. Während viele traditionell aufgestellte Call Center noch über die Pros und Cons der Nutzung von Social Media und Social Media Monitoring diskutieren und Apps erst versuchsweise in ihre Serviceprozesse integrieren, sind andere Branchen bereits viel weiter (Sohn 2012). Individueller Kundenservice durch Kontextinformationen Das exponentielle Ansteigen der Informationsflut und das Entstehen des so genannten Big Data Phänomens führt zu einer neuen Generation der smarten Informationsverarbeitung. Umfassende Serviceleistungen durch die neue App Economy Die nächste Generation an intelligenten Devices führt zu einer noch stärkeren virtuellen Erweiterung der Realität. Integration von Social Networks Der Kundenservice der Zukunft integriert zudem die bereits etablierten Social Networks. Bildnachweis: istockphoto Prof.
NodeXL: Network Overview, Discovery and Exploration for Excel Lost Customer Research: What Is It and When Is It Necessary Popular Today in Business: All Popular Articles This blog post is the first of a series of posts that I will be writing over the next few weeks about how to quickly and efficiently plan-out and execute a lost customer research project. This week’s post will explain what lost customer research is, why it is a useful market research tool, and when companies should consider launching this type of an initiative. What Is Lost Customer Research? Lost customer research is the process of gathering, analyzing, and interpreting the root causes as to why an individual customer or a group of customers has canceled their service contract and/or ceased using a company’s product. The purpose of this type of research is to attempt to identify trends in these losses, which can be used to improve a company’s overall understanding of its target customer and competitive positioning in the market place, while at the same time identifying product, service, and performance gaps and issues.
4 Promising Curation Tools That Help Make Sense of the Web Steven Rosenbaum is a curator, author, filmmaker and entrepreneur. He is the CEO of Magnify.net, a real-time video curation engine for publishers, brands, and websites. His book Curation Nation is slated to be published this spring by McGrawHill Business. As the volume of content swirling around the web continues to grow, we're finding ourselves drowning in a deluge of data. Where is the relevant material? The solution on the horizon is curation. In the past 90 days alone, there has been an explosion of new software offerings that are the early leaders in the curation tools category. 1. Storify co-founder Burt Herman worked as a reporter for the Associated Press during a 12-year career, six of those in news management as a bureau chief and supervising correspondent. At the AP, editors sending messages to reporters asking them to do a story would regularly write, “Can u pls storify?” Storify is currently invite only. 2. Scoop.it is often described as Tumblr without the blog. 3. 4.
Social Metrics to Watch: Exposure and Frequency Advertising on Facebook is currently a hot topic due to GM’s public pulling of its ads from the social network, which led many marketers to wonder if advertising on the social site is a smart move. After a year-long study, Resolution Media and Kenshoo are providing marketers with insights on the effectiveness of Facebook ads. The companies analyzed global data spanning 65 billion Facebook ad impressions and 20 million Facebook ad clicks over a wide range of brands and categories – including entertainment, finance, retail and insurance. “Social media has quickly become one of the preferred channels for brands, and when done right, can foster meaningful relationships between brands and consumers in ways that were never before possible,” says Alan Osetek, president of Resolution Media. However, some of the most interesting insights of the study regarded a new metric called “Exposure Rate,” which measures targeted engagement on Facebook.
Tagxedo - Tag Cloud with Styles A new era begins | Business Reporter Contact centres are on the brink of a revolution that will pay huge dividends for customers and companies A whole new role for contact centres beckons; that of rapidly understanding and efficiently communicating precise details about customer demand to the whole company. Armed with this insight, contact centres can now be equipped to serve the company’s internal customers better than ever before. How it’s done Combine the fact that customers use contact centres to talk to companies about everything, with a new ability to automatically monitor and understand what’s going on in every one of these conversations, and suddenly a company’s contact centre is transformed into a source of amazingly valuable information that can make a company more agile, responsive and profitable. Detailed and reliable information about what works for customers, and what doesn’t, is now available within hours of contact being made. Enormous potential Paddy Coleman is Managing Director of ASC telecom UK Ltd.