
A Simple Guide to the Versions of the Inception Network. The Inception network was an important milestone in the development of CNN classifiers.
Prior to its inception (pun intended), most popular CNNs just stacked convolution layers deeper and deeper, hoping to get better performance. The Inception network on the other hand, was complex (heavily engineered). It used a lot of tricks to push performance; both in terms of speed and accuracy. Its constant evolution lead to the creation of several versions of the network. The popular versions are as follows: Each version is an iterative improvement over the previous one. This blog post aims to elucidate the evolution of the inception network. This is where it all started. The Premise: Salient parts in the image can have extremely large variation in size. How To Make Custom AI-Generated Text With GPT-2. In February 2019, OpenAI released a paper describing GPT-2, a AI-based text-generation model based on the Transformer architecture and trained on massive amounts of text all around the internet.
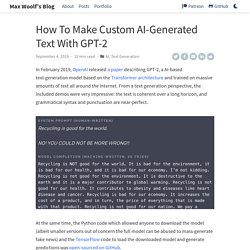
From a text-generation perspective, the included demos were very impressive: the text is coherent over a long horizon, and grammatical syntax and punctuation are near-perfect. At the same time, the Python code which allowed anyone to download the model (albeit smaller versions out of concern the full model can be abused to mass-generate fake news) and the TensorFlow code to load the downloaded model and generate predictions was open-sourced on GitHub. Neil Shepperd created a fork of OpenAI’s repo which contains additional code to allow finetuning the existing OpenAI model on custom datasets. Better Language Models and Their Implications: Feb 2019 state of the art text generation.
View codeRead paper Our model, called GPT-2 (a successor to GPT), was trained simply to predict the next word in 40GB of Internet text.

Due to our concerns about malicious applications of the technology, we are not releasing the trained model. As an experiment in responsible disclosure, we are instead releasing a much smaller model for researchers to experiment with, as well as a technical paper. GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset of 8 million web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some text. GPT-2 displays a broad set of capabilities, including the ability to generate conditional synthetic text samples of unprecedented quality, where we prime the model with an input and have it generate a lengthy continuation. Samples. AI Weirdness: Archive. Karpathy/char-rnn: NN to generate text used to create pokemon.
Computer Learns To Create Its Own Pokémon, And They're Great.
CIFAR-10 and CIFAR-100 datasets. < Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class.
There are 50000 training images and 10000 test images. The dataset is divided into five training batches and one test batch, each with 10000 images. Here are the classes in the dataset, as well as 10 random images from each: The classes are completely mutually exclusive. Download If you're going to use this dataset, please cite the tech report at the bottom of this page. Baseline results. Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks. Recognizing Objects with Deep Learning You might have seen this famous xkcd comic before.
The goof is based on the idea that any 3-year-old child can recognize a photo of a bird, but figuring out how to make a computer recognize objects has puzzled the very best computer scientists for over 50 years. In the last few years, we’ve finally found a good approach to object recognition using deep convolutional neural networks. That sounds like a a bunch of made up words from a William Gibson Sci-Fi novel, but the ideas are totally understandable if you break them down one by one.
So let’s do it — let’s write a program that can recognize birds! Starting Simple Before we learn how to recognize pictures of birds, let’s learn how to recognize something much simpler — the handwritten number “8”. In Part 2, we learned about how neural networks can solve complex problems by chaining together lots of simple neurons. Datasets for Data Mining and Data Science.
See also Data repositories AssetMacro, historical data of Macroeconomic Indicators and Market Data.
Awesome Public Datasets on github, curated by caesar0301. AWS (Amazon Web Services) Public Data Sets, provides a centralized repository of public data sets that can be seamlessly integrated into AWS cloud-based applications. BigML big list of public data sources. Related. Ssathya/IMDBMongo: Process files from IMDB ... Installation - TFLearn. Tensorflow Installation TFLearn requires Tensorflow (version >= 0.9.0) to be installed.
Select the correct binary to install, according to your system: # Ubuntu/Linux 64-bit, CPU only, Python 2.7 $ export TF_BINARY_URL= # Ubuntu/Linux 64-bit, GPU enabled, Python 2.7# Requires CUDA toolkit 7.5 and CuDNN v5. For other versions, see "Install from sources" below. $ export TF_BINARY_URL= # Mac OS X, CPU only, Python 2.7: $ export TF_BINARY_URL= # Mac OS X, GPU enabled, Python 2.7: $ export TF_BINARY_URL= # Ubuntu/Linux 64-bit, CPU only, Python 3.4 $ export TF_BINARY_URL= # Ubuntu/Linux 64-bit, GPU enabled, Python 3.4# Requires CUDA toolkit 7.5 and CuDNN v5. Numpy.ndarray — NumPy v1.12 Manual.
Scipy.ndimage.imread — SciPy v0.14.0 Reference Guide. Download and Setup You can install TensorFlow either from our provided binary packages or from the github source.
Requirements. Neural networks and deep learning. In the last chapter we learned that deep neural networks are often much harder to train than shallow neural networks.
That's unfortunate, since we have good reason to believe that if we could train deep nets they'd be much more powerful than shallow nets. But while the news from the last chapter is discouraging, we won't let it stop us. In this chapter, we'll develop techniques which can be used to train deep networks, and apply them in practice. We'll also look at the broader picture, briefly reviewing recent progress on using deep nets for image recognition, speech recognition, and other applications.