
Basics_introduction_1. Basics_introduction_2. Basic Terminologies. We need to know few basic terminologies with respect to Storage , Network,Data Processing before we get into more detail on Hadoop Architecture and File System .
SEEK TIME - is the time taken for a hard disk controller or pointer to locate a specific piece of stored data. Other delays include transfer time (data rate) and rotational delay (latency). LATENCY - is the time required to perform some action or to produce some result. Latency is measured in units of time — hours, minutes, seconds, nanoseconds or clock periods. THROUGHPUT- is the amount of data that can traverse through a given medium ( Bandwidth is nothing but the diameter of your medium ) FAULT TOLERANCE – Your system should have the ability to respond gracefully and continue the operations during the unexpected failure of your system like Power,Hardware,Data corruption,etc. RAID - Collection of Disks storing the same data ( mirroring) in different places . Like this: Like Loading... Subprojects of Hadoop. What is Kerberos Authentication? What is URI ? and Difference between URI,URL and URN ? What is URI ?
And how different from URL ? URI stands for Universal Resource IdentifierURL stands for Universal Resource LocatorURN stands for Universal Resource Name URI is combination of URL + URNURI is protocol to retrieve the resource or location. protocol example : , , (local machine) , mailto: URL will always contain protocol and location to retrieve the resource. URN is subset of URI. Every URL is URIEvery URN is URI URI -> -> The first is missing the extension, so it could be a directory or a file or whatever (simply a location of a resource named “w3c_home”). All three URI, URL and URN are used to identify any resource or name in internet but there is small difference between them explained above. Like this: Like Loading... Hadoop-architecture_1.
Hadoop-architecture_2. Rack awareness. Vmware setup with Ubuntu. Hadoop Single node Cluster Installation. Hadoop FS commands. MapReduce. Hadoop 1.2.1 Eclipse Setup. Trying out java code through Command Line would be difficult .
We will configure the Hadoop in Eclipse and run the same java WordCount example and see the results. 1. For Ubuntu users, Go to Ubuntu Software Center , Search for eclipse keyword. Or download from eclipse website ( Eclipse Indigo version ) 2.Install the software ( eclipse indigo version is available in Ubuntu Software Center) 3.Open Eclipse and create your workspace with your directory choice. Note : Those who get some error like this java.lang.UnsatisfiedLinkError: Could not load SWT library. On Ubuntu 12.04 32 bit.run this command : ln -s /usr/lib/jni/libswt-* ~/.swt/lib/linux/x86/ on Ubuntu 12.04 64 bit try: ln -s /usr/lib/jni/libswt-* ~/.swt/lib/linux/x86_64/ 4.create a Java Project 5.Add the required libraries in Project properties – Tab : Libraries – Add External Jars Files under /usr/local/hadoop All Jar files ( Actually all jar are not required to run our simple wordcount example, for your advance learning, it might required )
Explaination about Hadoop Versions. In version control , A trunk is considered your main code base.
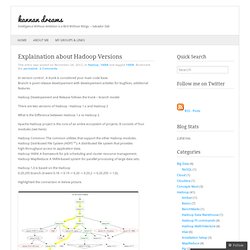
Branch is point release developement with developement activties for bugfixes, additional features. Hadoop Developement and Release follows the trunk – branch model. There are two versions of Hadoop : Hadoop 1.x and Hadoop 2 What is the Difference between Hadoop 1.x vs Hadoop 2 Apache Hadoop project is the core of an entire ecosystem of projects. Hadoop Common: The common utilities that support the other Hadoop modules. Hadoop 1.0 is based on the Hadoop 0.20.205 branch (it went 0.18 -> 0.19 -> 0.20 -> 0.20.2 -> 0.20.205 -> 1.0). Highlighted the connection in below picture. So we call 0.20.205 as 1.0 and consider this release as stable to that point. Some explanations for the diagram: Green rectangles designate official Apache Hadoop releases openly available for anyone in the world for freeBlack ovals show Hadoop branches that are not yet officially released by Apache Hadoop (or might not be released ever).