
Parallel computing. The maximum possible speed-up of a single program as a result of parallelization is known as Amdahl's law.
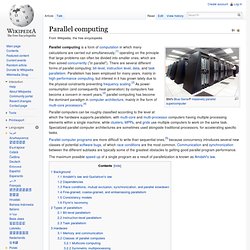
Background[edit] Traditionally, computer software has been written for serial computation. Application programming interface. In computer programming, an application programming interface (API) specifies how some software components should interact with each other.
Detailed explanation[edit] API in procedural languages[edit] In most procedural languages, an API specifies a set of functions or routines that accomplish a specific task or are allowed to interact with a specific software component. This specification is presented in a human readable format in paper books, or in electronic formats like ebooks or as man pages. For example, the math API on Unix systems is a specification on how to use the mathematical functions included in the math library. The Unix command man 3 sqrt presents the signature of the function sqrt in the form: SYNOPSIS #include <math.h> double sqrt(double X); float sqrtf(float X); DESCRIPTION sqrt computes the positive square root of the argument.
. . . . $ perldoc -f sqrt sqrt EXPR sqrt #Return the square root of EXPR. Thread (computer science) A process with two threads of execution on a single processor On a single processor, multithreading is generally implemented by time-division multiplexing (as in multitasking): the processor switches between different threads.
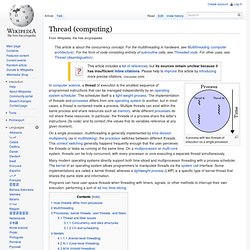
This context switching generally happens frequently enough that the user perceives the threads or tasks as running at the same time. On a multiprocessor or multi-core system, threads can be truly concurrent, with every processor or core executing a separate thread simultaneously. Systems such as Windows NT and OS/2 are said to have "cheap" threads and "expensive" processes; in other operating systems there is not so great difference except the cost of address space switch which implies a TLB flush. Scheduling in Distributed Computing Systems: Analysis, Design and Models (9780387744803): Deo Prakash Vidyarthi, Biplab Kumer Sarker, Anil Kumar Tripathi, Laurence Tianruo Yang.
Cluster Analysis for Researchers (9781411606173): Charles Romesburg. 4q01-Lin.pdf (application/pdf Objeto) Super-threading. While this approach enables better use of the processor's resources, further improvements to resource utilization can be realized through SMT, which allows the execution of instructions from multiple threads at the same time.
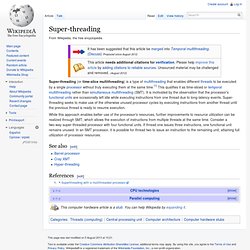
Consider a two-way super-threaded processor with four functional units. If thread one issues three instructions, one functional unit remains unused. In an SMT processor, it is possible for thread two to issue an instruction to the remaining unit, attaining full utilization of processor resources. Hyper-threading. A high-level depiction of the Intel's Hyper-Threading Technology Hyper-threading (officially Hyper-Threading Technology or HT Technology, abbreviated HTT or HT) is Intel's proprietary simultaneous multithreading (SMT) implementation used to improve parallelization of computations (doing multiple tasks at once) performed on x86 microprocessors.
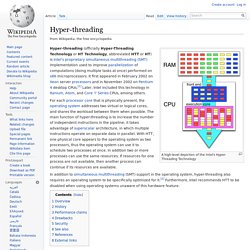
It first appeared in February 2002 on Xeon server processors and in November 2002 on Pentium 4 desktop CPUs.[1] Later, Intel included this technology in Itanium, Atom, and Core 'i' Series CPUs, among others. For each processor core that is physically present, the operating system addresses two virtual or logical cores, and shares the workload between them when possible. Personal computer hardware. Software is any set of machine-readable instructions that directs a computer's processor to perform specific operations.
A combination of hardware and software forms a usable computing system.[2] Von Neumann architecture[edit] Von Neumann architecture scheme. Linux, migración a software libre, consolidación de servidores, terminales, clusters de alto rendimiento y tolerantes a fallos en Andalucía (Espańa) 8. Parallel Computing Techniques. 8.3 Parallel Computing Software. How to Build a Parallel Computing Cluster. In this howto, we are going to describe the procedure of building a diskless parallel computing cluster for computational physics.

First of all, we will give a brief overview of Linux Operating system. Based on this knowledge, we hope readers will have a better understanding of the whole setup procedure. This howto is divided into the following section. Introduction. Overview of Linux Operating system. Introduction Computer simulation is a powerful tool for the study of complex systems.
To solve a complex problem correctly and efficiently, there are several concerns in computational physics. The original PC cluster project, also called Beowulf project, was started at the Center of Excellence in Space Data and Information Sciences NASA in early 1994. The advantages of a Beowulf-like cluster are: Hardware is available from multiple sources that means low prices and easy maintenance. Hardware Configuration Software Configuration. Introduction to Parallel Computing and Cluster Computers. Designing a Cluster Computer. Designing a Cluster Computer Choosing a processor Best performance for the price ==> PC (currently dual-Xeon systems) If maximizing memory and/or disk is important, choose faster workstations For maximum bandwidth, more expensive workstations may be needed HINT benchmark developed at the SCL, or a similar benchmark based on the DAXPY kernel shown below, show the performance of each processor for a range of problem sizes.

Designing the network Netpipe graphs can be very useful in characterizing the different network interconnects, at least from a point-to-point view. Which OS? Loading up the software Assembling the cluster Pre-built clusters . Multi-core processor. Diagram of a generic dual-core processor, with CPU-local level 1 caches, and a shared, on-die level 2 cache.
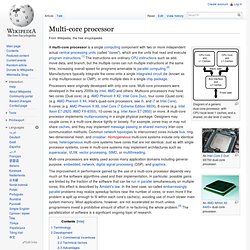
Multi-core processors are widely used across many application domains including general-purpose, embedded, network, digital signal processing (DSP), and graphics. The improvement in performance gained by the use of a multi-core processor depends very much on the software algorithms used and their implementation. In particular, possible gains are limited by the fraction of the software that can be run in parallel simultaneously on multiple cores; this effect is described by Amdahl's law. In the best case, so-called embarrassingly parallel problems may realize speedup factors near the number of cores, or even more if the problem is split up enough to fit within each core's cache(s), avoiding use of much slower main system memory.