
8天学通MongoDB——第三天 细说高级操作 - 一线码农. 今天跟大家分享一下mongodb中比较好玩的知识,主要包括:聚合,游标。
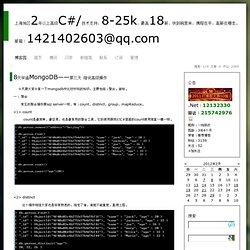
一: 聚合 常见的聚合操作跟sql server一样,有:count,distinct,group,mapReduce。 <1> count count是最简单,最容易,也是最常用的聚合工具,它的使用跟我们C#里面的count使用简直一模一样。 <2> distinct 这个操作相信大家也是非常熟悉的,指定了谁,谁就不能重复,直接上图。 <3> group 在mongodb里面做group操作有点小复杂,不过大家对sql server里面的group比较熟悉的话还是一眼 能看的明白的,其实group操作本质上形成了一种“k-v”模型,就像C#中的Dictionary,好,有了这种思维, 我们来看看如何使用group。 下面举的例子就是按照age进行group操作,value为对应age的姓名。 Key: 这个就是分组的key,我们这里是对年龄分组。 Initial: 每组都分享一个”初始化函数“,特别注意:是每一组,比如这个的age=20的value的list分享一个. 网易杭州实践者论坛(2013年4月期)预览 - 网易云课堂.
Yet another MongoDB Map Reduce tutorial. Background As the title says, this is yet-another-tutorial on Map Reduce using MongoDB.
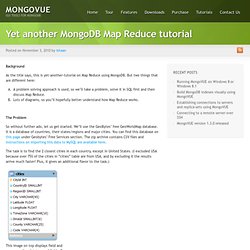
But two things that are different here: A problem solving approach is used, so we’ll take a problem, solve it in SQL first and then discuss Map Reduce. Lots of diagrams, so you’ll hopefully better understand how Map Reduce works. The Problem So without further ado, let us get started. The task is to find the 2 closest cities in each country, except in United States. Assumptions For sake of simplicity, we’ll represent earth as a 2D plane. SQL Solution If the distance between each pair of cities in a country were known then we could simply apply a GROUP BY statement where we divide the data by Country and find those two cities where the distance is minimum. Now that we have distance between each pair of cities, we can now group this data by country and then proceed to select those 2 cities that have the least value for “Dist” field but still greater than zero. It is important to note the steps we followed.
Quick and dirty (incomplete) list of interesting, mostly recent data warehousing/"big data" papers. A friend asked me for a few pointers to interesting, mostly recent papers on data warehousing and "big data" database systems, with an eye towards real-world deployments.
I figured I'd share the list. It's biased and rather incomplete but maybe of interest to someone. While many are obvious choices (I've omitted several, like MapReduce), I think there are a few underappreciated gems. Dataflow Engines: Dryad--general-purpose distributed parallel dataflow Spark--in memory Streaming and Matviews Spark Streaming--building streaming on top of a distributed data flow Nectar--reusing previously computed results in dataflows (HT @squarecog) Differential dataflow: fresh take on incremental computation and DBToaster: fast, modern materialized view TelegraphCQ: good example of (old) stream processing systems--useful to contrast to, say, Borealis: research distributed stream processing system from the 2000s (HT @marcua) Full-stack "Database System" Category Mostly OLAP C-Store: columnar storage, now Scheduling.
Readings in Databases. A list of papers essential to understanding databases and building new data systems.
Basics The Five-Minute Rule Ten Years Later, and Other Computer Storage Rules of Thumb: This paper (and the original one proposed 10 years earlier) illustrates a quantitative formula to calculate whether a data page should be cached in memory or not. It is a delight to read Jim Gray approach to an array of related problems, e.g. how big should a page size be. Paxos Made Simple: Paxos is a fault-tolerant distributed consensus protocol.
It forms the basis of a wide variety of distributed systems. AlphaSort: A Cache-Sensitive Parallel External Sort. PaaS正能量:6人团队,仅1人全职后端 支撑6000万用户. 摘要:6人团队,仅1人全职后端,可以支撑起日百万活跃用户的线上活动?
SongPop用事实告诉我们,利用好PaaS这是完全可行的! 而从PaaS上获益的绝不是SongPop他们一个,近日Google博客上贴出了一些GAE的用例,其中包括:“Angry Birds”的拥有者Rovio,Ruzzle拥有者MAG Interactive等。 相信有很多人对PaaS持谨慎态度,到底是用还是不用? 而在前一阶段“ 用户指责Heroku私自修改路由机制造成高支出”这场风暴过境后,PaaS似乎变的更加让人望而却步了。 然则PaaS真像这些负面所说,高投入之后却带不来应有的回报? SongPop SongPop,音乐版你画我猜游戏;于2012年5月上线,现已拥有6000万个用户,位列2012年iOS游戏下载榜第5。 Return of the Borg: How Twitter Rebuilt Google's Secret Weapon. Illustration: Ross Patton John Wilkes says that joining Google was like swallowing the red pill in The Matrix.
Four years ago, Wilkes knew Google only from the outside. He was among the millions whose daily lives so deeply depend on things like Google Search and Gmail and Google Maps. But then he joined the engineering team at the very heart of Google’s online empire, the team of big thinkers who design the fundamental hardware and software systems that drive each and every one of the company’s web services. These systems span a worldwide network of data centers, responding to billions of online requests with each passing second, and when Wilkes first saw them in action, he felt like Neo as he downs the red pill, leaves the virtual reality of the Matrix, and suddenly lays eyes on the vast network of machinery that actually runs the thing.
“I’m an old guy. ‘I prefer to call it the system that will not be named.’ — John Wilkes The Borg moniker is only appropriate. . — Ben Hindman.