
Département Informatique Cnam Paris. Avant-Propos. Le but de ce cours est de donner une idée de la programmation, algorithmique et sémantique de systèmes parallèles et distribués.

Pour y arriver, on utilise un biais dans un premier temps, qui nous permettra d'aborder les principaux thèmes du domaine. On va utiliser le système de ``threads'' de JAVA pour simuler des processus parallèles et distribués. Plus tard, on utilisera d'autres fonctionnalités de JAVA, comme les RMI, pour effectuer véritablement des calculs en parallèle sur plusieurs machines. Les ``threads'' en tant que tels sont une première approche du parallélisme qui peut même aller jusqu'au ``vrai parallélisme'' sur une machine multi-processeurs.
Pour avoir un panorama un peu plus complet du parallélisme et de la distribution, il faut être capable de faire travailler plusieurs machines (éventuellement très éloignées l'une de l'autre; penser à internet) en même temps. Il existe des compilateurs qui parallélisent automatiquement des codes séquentiels. Références.
DSM Distributed Shared Memory. Category:Distributed computing architecture. Architectural, organisational, and engineering aspects of distributed computing.
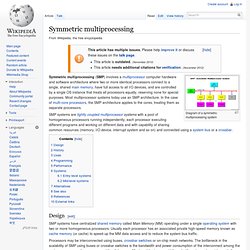
Computer architectures, software architectures, software frameworks, and network architectures related to distributed computing and distributed systems. Different “styles” of distributed computing. See also[edit] Communication protocols and standards related to distributed computing: Programming languages and tools related to distributed computing: Subcategories This category has the following 17 subcategories, out of 17 total. Symmetric multiprocessing. Diagram of a symmetric multiprocessing system Symmetric multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors connect to a single, shared main memory, have full access to all I/O devices, and are controlled by a single OS instance that treats all processors equally, reserving none for special purposes.
Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors. Asymmetric multiprocessing. Asymmetric multiprocessing (AMP) was a software stopgap for handling multiple CPUs before symmetric multiprocessing (SMP) was available.
It has also been used to provide less expensive options[1] on systems where SMP was available. In an asymmetric multiprocessing system, not all CPUs are treated equally; for example, a system might only allow (either at the hardware or operating system level) one CPU to execute operating system code or might only allow one CPU to perform I/O operations. Other AMP systems would allow any CPU to execute operating system code and perform I/O operations, so that they were symmetric with regard to processor roles, but attached some or all peripherals to particular CPUs, so that they were asymmetric with regard to peripheral attachment. Asymmetric multiprocessing Multiprocessing is the use of more than one CPU in a computer system. Supercomputer. The Blue Gene/P supercomputer at Argonne National Lab runs over 250,000 processors using normal data center air conditioning, grouped in 72 racks/cabinets connected by a high-speed optical network[1] A supercomputer is a computer at the frontline of contemporary processing capacity – particularly speed of calculation which can happen at speeds of nanoseconds.
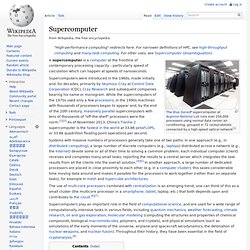
The use of multi-core processors combined with centralization is an emerging trend; one can think of this as a small cluster (the multicore processor in a smartphone, tablet, laptop, etc.) that both depends upon and contributes to the cloud.[6][7] History[edit] The CDC 6600, released in 1964, was designed by Cray to be the fastest in the world by a large margin. While the supercomputers of the 1980s used only a few processors, in the 1990s, machines with thousands of processors began to appear both in the United States and in Japan, setting new computational performance records.
Simultaneous multithreading. Details[edit] Multithreading is similar in concept to preemptive multitasking but is implemented at the thread level of execution in modern superscalar processors.
Simultaneous multithreading (SMT) is one of the two main implementations of multithreading, the other form being temporal multithreading. Superscalar. Simple superscalar pipeline.
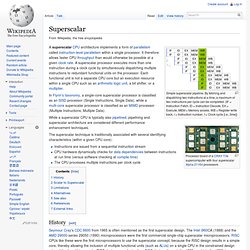
By fetching and dispatching two instructions at a time, a maximum of two instructions per cycle can be completed. (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = Memory access, WB = Register write back, i = Instruction number, t = Clock cycle [i.e., time]) Vector processor. Other CPU designs may include some multiple instructions for vector processing on multiple (vectorised) data sets, typically known as MIMD (Multiple Instruction, Multiple Data) and realized with VLIW.
Such designs are usually dedicated to a particular application and not commonly marketed for general purpose computing. In the Fujitsu FR-V VLIW/vector processor both technologies are combined. History[edit] Early work[edit] Beowulf (computing) The Borg, a 52-node Beowulf cluster used by the McGill Universitypulsar group to search for pulsations from binary pulsars A Beowulf cluster is a computer cluster of what are normally identical, commodity-grade computers networked into a small local area network with libraries and programs installed which allow processing to be shared among them.
Massively parallel. Amdahl's law. The speedup of a program using multiple processors in parallel computing is limited by the sequential fraction of the program.

For example, if 95% of the program can be parallelized, the theoretical maximum speedup using parallel computing would be 20× as shown in the diagram, no matter how many processors are used. Amdahl's law, also known as Amdahl's argument,[1] is used to find the maximum expected improvement to an overall system when only part of the system is improved. Flynn's taxonomy. Flynn's taxonomy is a classification of computer architectures, proposed by Michael J.
Flynn in 1966.[1][2] Classifications[edit] The four classifications defined by Flynn are based upon the number of concurrent instruction (or control) and data streams available in the architecture: Single Instruction, Single Data stream (SISD) Speedup. In parallel computing, speedup refers to how much a parallel algorithm is faster than a corresponding sequential algorithm.
Definition[edit] Speedup is defined by the following formula: where: Cost efficiency. Cost efficiency (or cost optimality), in the context of parallel computer algorithms, refers to a measure of how effectively parallel computing can be used to solve a particular problem. A parallel algorithm is considered cost efficient if its asymptotic running time multiplied by the number of processing units involved in the computation is comparable to the running time of the best sequential algorithm. For example, an algorithm that can be solved in time using the best known sequential algorithm and. Gustafson's law. Gustafson's Law Gustafson's Law (also known as Gustafson–Barsis' law) is a law in computer science which says that computations involving arbitrarily large data sets can be efficiently parallelized. Gustafson's Law provides a counterpoint to Amdahl's law, which describes a limit on the speed-up that parallelization can provide, given a fixed data set size.
Gustafson's law was first described [1] by John L. Gustafson and his colleague Edwin H. Barsis: where P is the number of processors, S is the speedup, and the non-parallelizable fraction of any parallel process. Parallel computing. The maximum possible speed-up of a single program as a result of parallelization is known as Amdahl's law. Background[edit] Traditionally, computer software has been written for serial computation. To solve a problem, an algorithm is constructed and implemented as a serial stream of instructions. These instructions are executed on a central processing unit on one computer. Karp–Flatt metric. Cesames. UeNSY104.pdf (Objet application/pdf)